
GWCTF2019re3
链接:https://pan.baidu.com/s/1lZr8Cqf8FOuwOU-x2J3yVQ
提取码:myh6
知识点总结: 🚦
ECB模式 平均分组 每组互不干扰
CBC模式 平均分组 改明文和前一个密文异或之后再进行加密 所以需要一个初始化数组对第一组异或
一般来说AES加密前会调用一个函数对密匙进行拓展 然后才会处理明
0X01 查看有无加壳 🍖
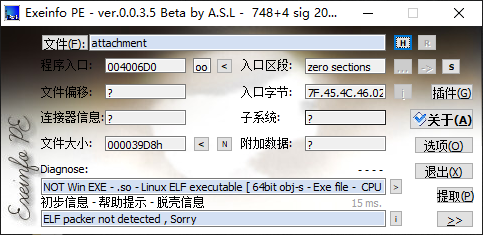
没有加壳,64位文件
0x02 使用IDA64打开文件 🔑
- 找到main函数, F5 反编译,进行代码分析
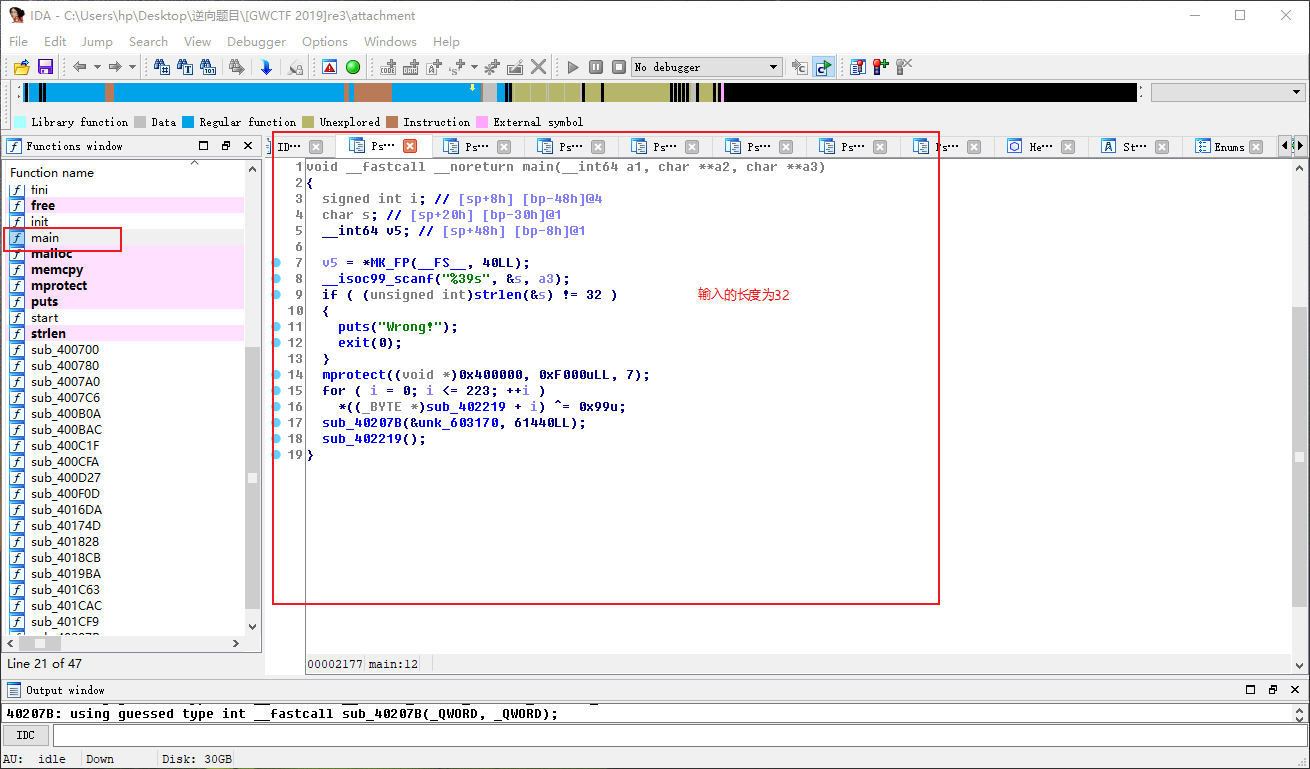
1 | void __fastcall __noreturn main(__int64 a1, char **a2, char **a3) |
- sub_4022190函数有异或,我们查看
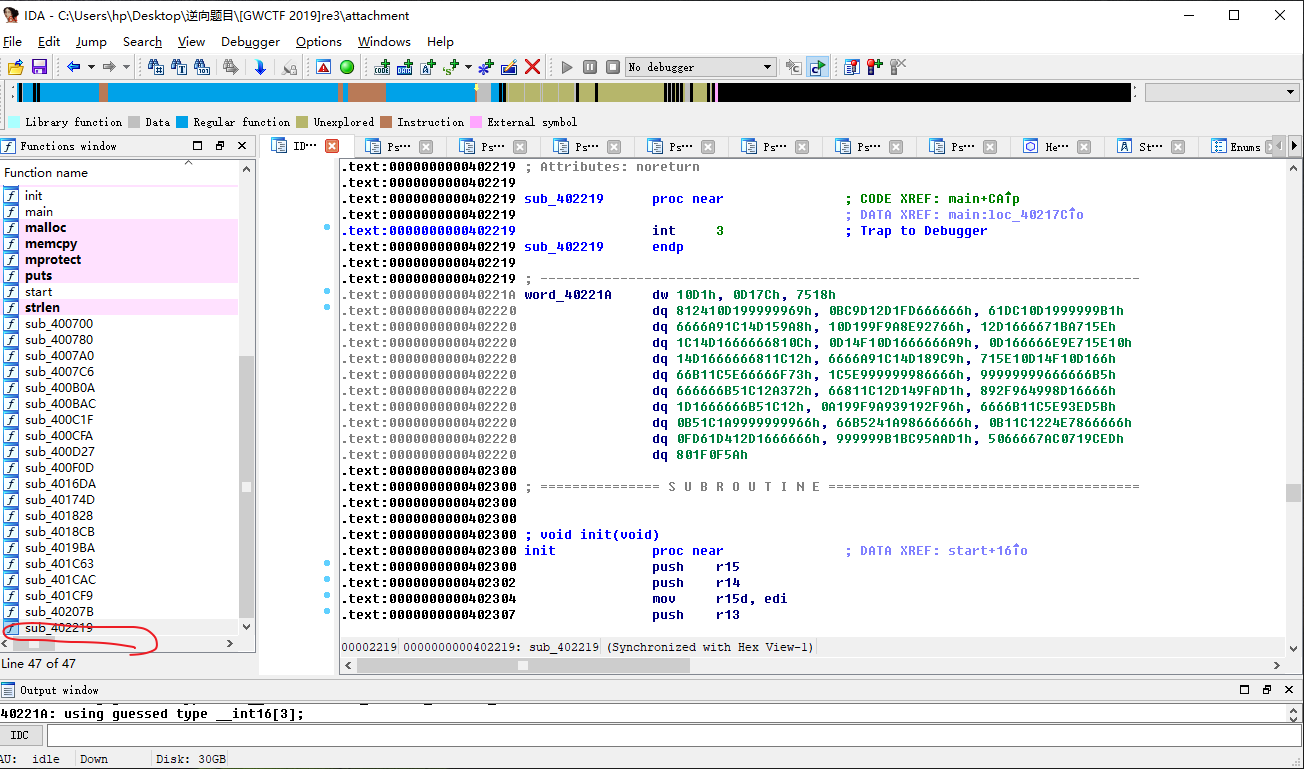
- 选中后我们按
C强制(Force)分析代码
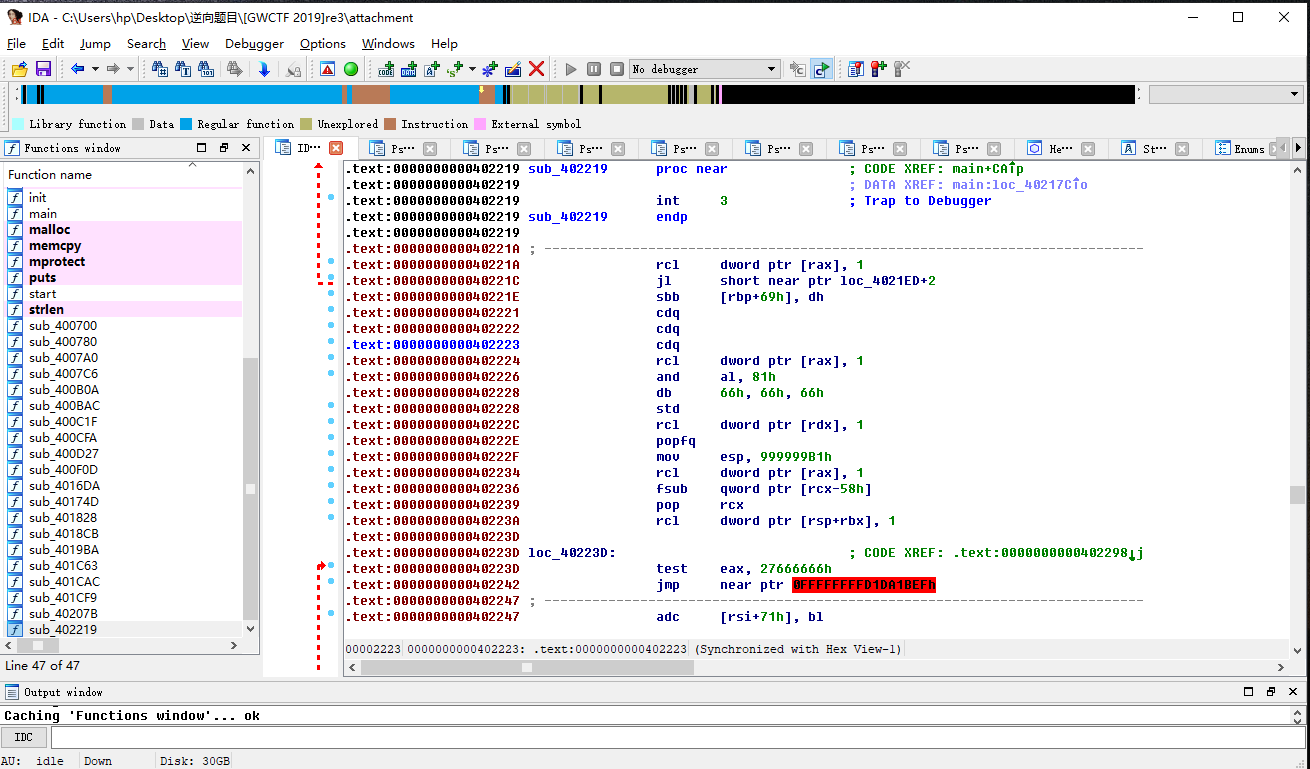
使用Findecrypt插件查看一下加密算法发现很多加密
- 我们查看sub_40207B()函数
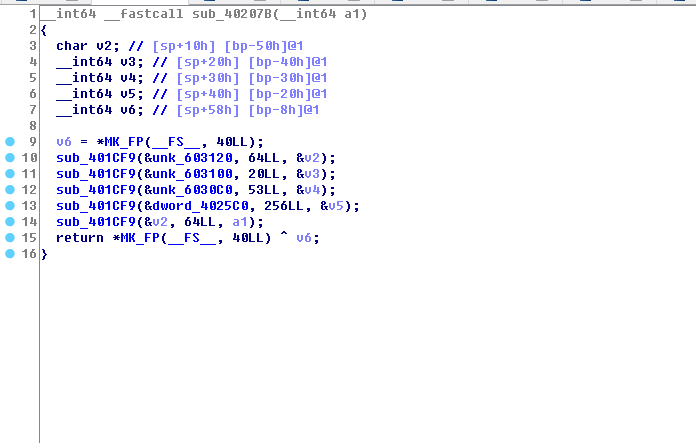
MD5加密,第10行和14行的MD5加密有用
内容大体将base64密码表进行两次sub_401CF9加密然后赋值给参数a1
这里没有用到用户输入,可以动调一下获得加密后的a1
IDA先在sub_40207B()函数执行后一条下断点
**0x03 写个脚本做循环对比就行了 ** 🎅
1 | from Crypto.Cipher import AES |
so.in内容
1 | BC 0A AD C0 14 7C 5E CC E0 B1 40 BC 9C 51 D5 2B |
从零开始python学习第五天
从零考试学习python内容 99%来自于python大神 python-jack的知乎文章 再结合本人的实际情况进行学习,严格来说这是JACK老师的内容,只不过再此基础上,我增添了一些我在CTF解题过程中遇到的python脚本实际情况,再次感谢JACK老师
第010课:函数和字符串的应用
前面两节课,我们介绍了函数和字符串。在讲解今天的内容之前,先来回答一个可能会让大家感到费解的问题:为什么字符串类型(str)可以通过调用方法的方式进行操作,而之前我们用到的数值类型(如int、float)却没有可以调用的方法。在Python中,数值类型是标量类型,也就是说这种类型的变量没有可以访问的内部结构;而字符串类型是一种结构化的、非标量类型,所以才会有一系列的方法可供调用。如果对这一点感到困惑,那就继续学习吧,等学习完面向对象编程的知识后,你就能找到这些问题的答案了。
一些案例
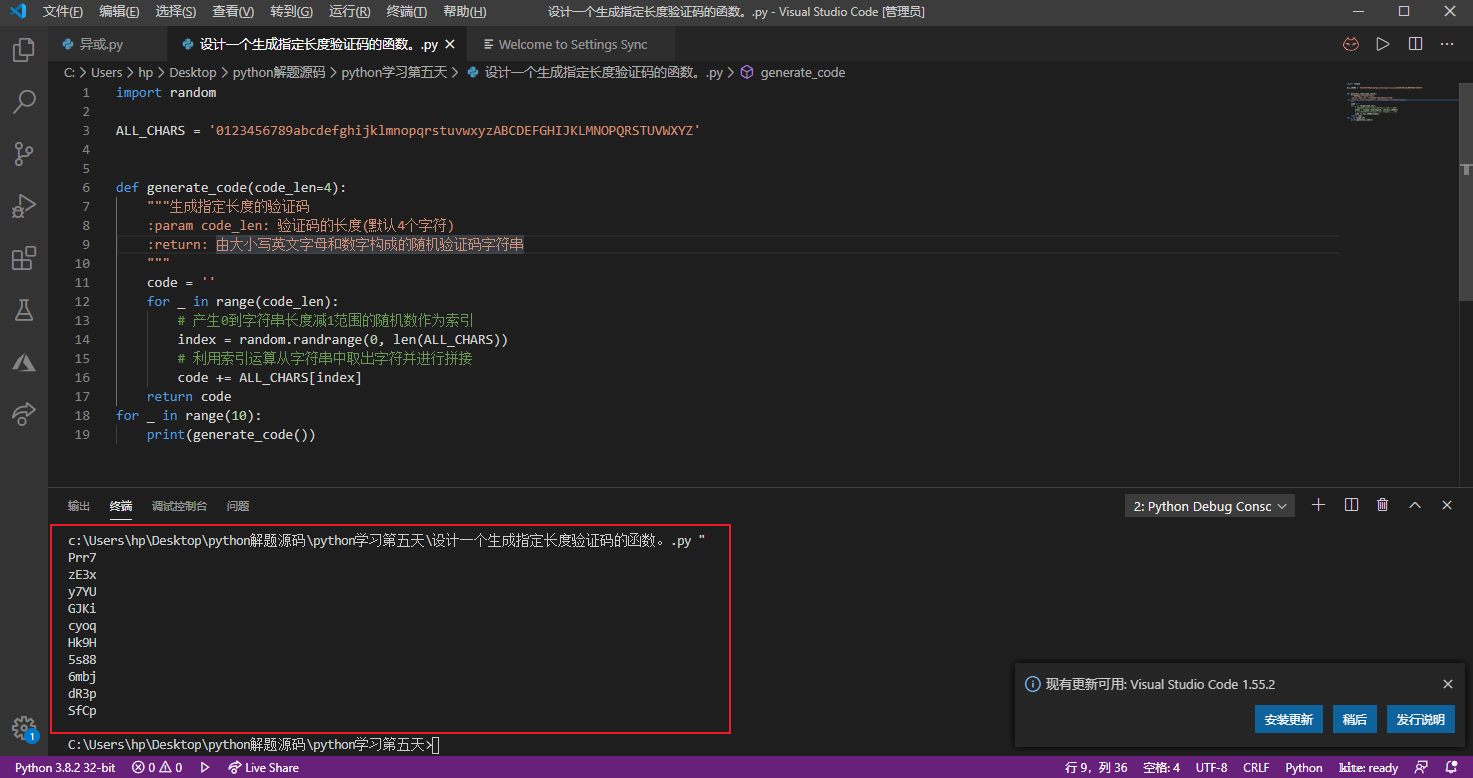
**例子1:设计一个生成指定长度验证码的函数。 🅰️ **
说明:验证码由数字和英文大小写字母构成。
1 | import random |
我们用下面的代码生成10组随机验证码来测试上面的函数( 没有下面的代码就无法运行 )。
1 | for _ in range(10): |
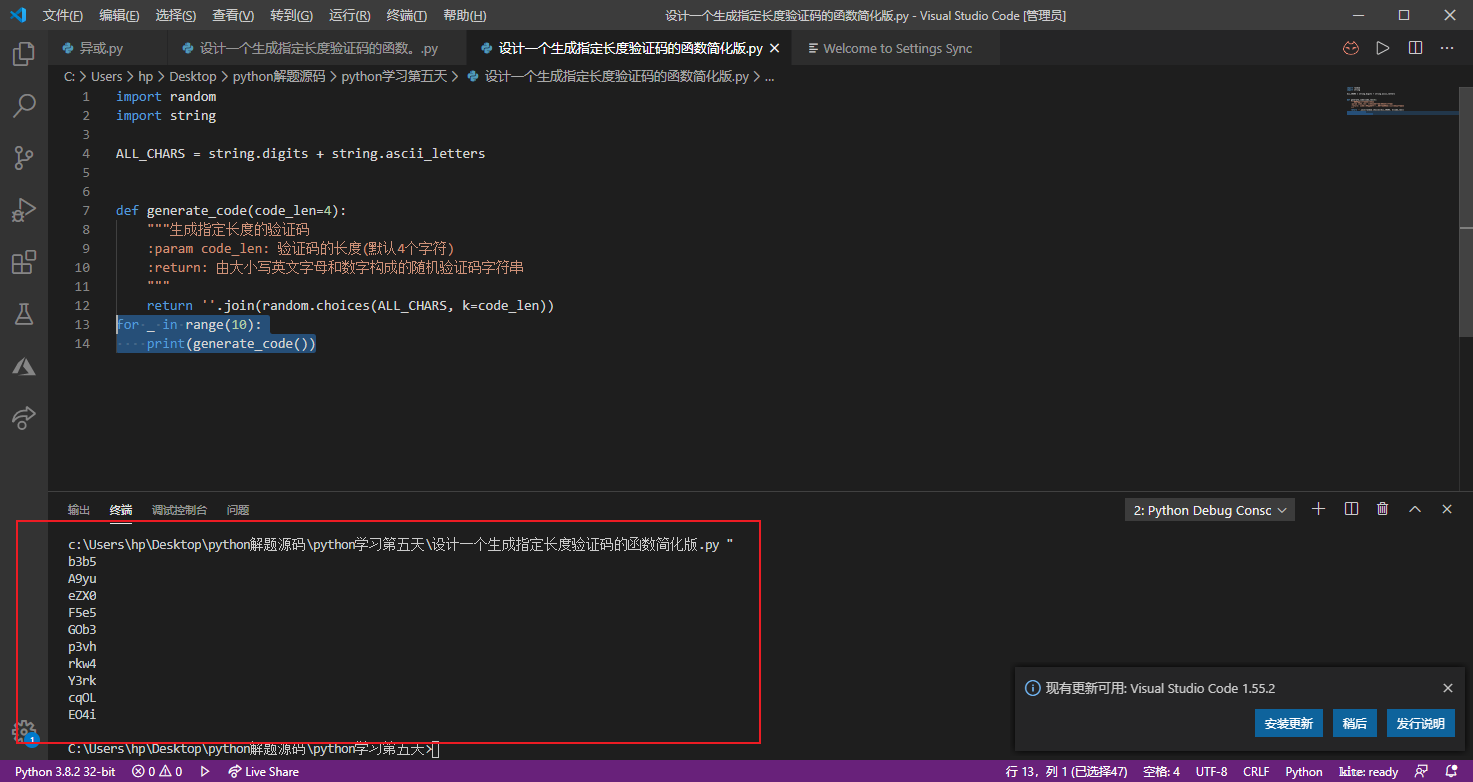
上面的函数其实还有一种更为简单的写法,直接利用random模块的随机抽样函数从字符串中取出指定数量的字符,然后利用字符串的join方法将选中的那些字符拼接起来。此外,可以利用Python标准库中的string 模块来获得数字和英文字母的字面常量。
1 | import random |
说明:
random模块的sample和choices函数都可以实现随机抽样,sample实现无放回抽样,这意味着抽样取出的字符是不重复的;choices实现有放回抽样,这意味着可能会重复选中某些字符。这两个函数的第一个参数代表抽样的总体,而参数k代表抽样的数量。
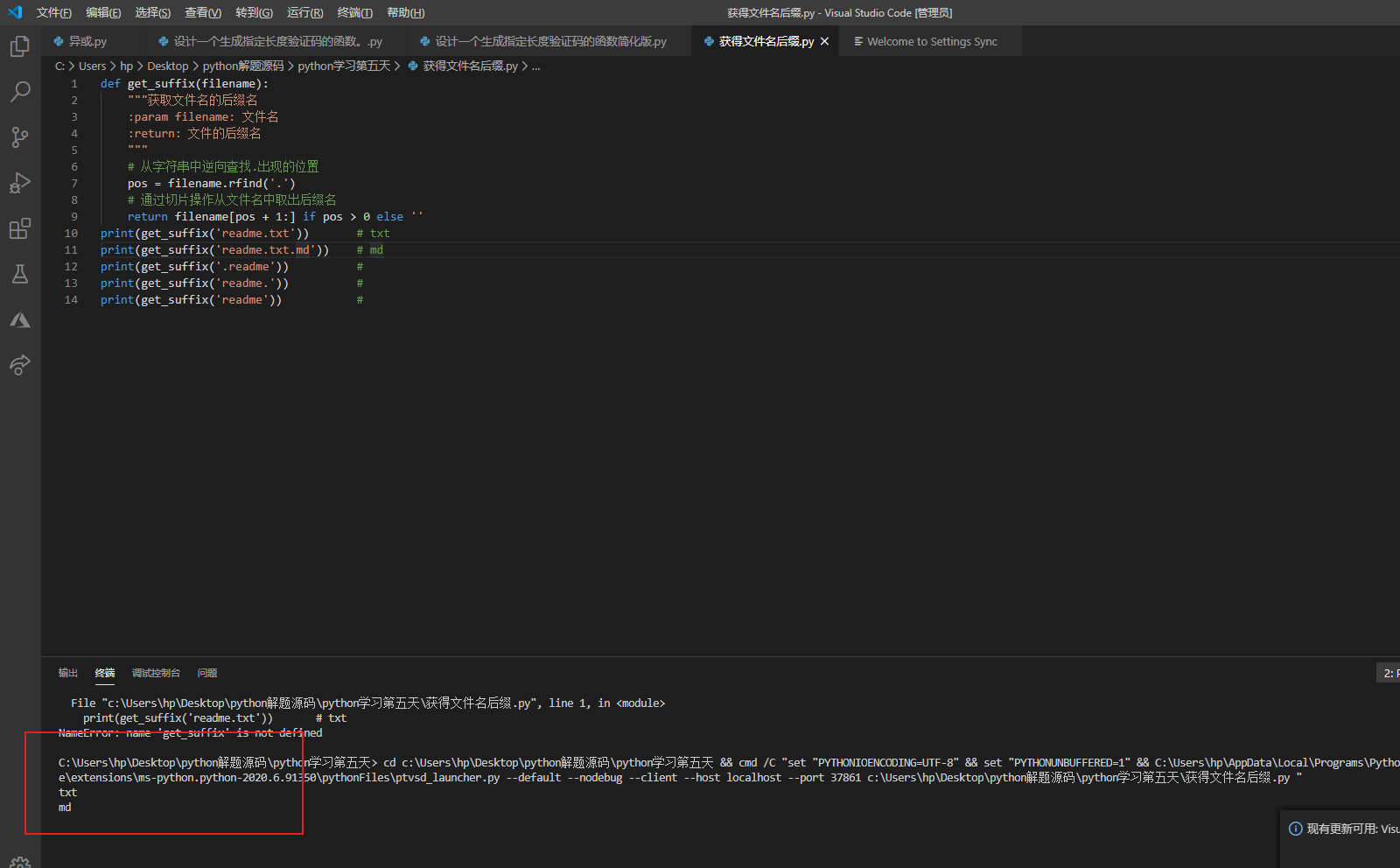
例子2:设计一个函数返回给定文件名的后缀名。 🅱️
说明:文件名通常是一个字符串,而文件的后缀名指的是文件名中最后一个
.后面的部分,也称为文件的扩展名,它是某些操作系统用来标记文件类型的一种机制,例如在Windows系统上,后缀名exe表示这是一个可执行程序,而后缀名txt表示这是一个纯文本文件。需要注意的是,在Linux和macOS系统上,文件名可以以.开头,表示这是一个隐藏文件,像.gitignore这样的文件名,.后面并不是后缀名,这个文件没有后缀名或者说后缀名为''。
1 | def get_suffix(filename): |
可以用下面的代码对上面的函数做一个简单的测验。
1 | print(get_suffix('readme.txt')) # txt |
上面的get_suffix函数还有一个更为便捷的实现方式,就是直接使用os.path模块的splitext函数,这个函数会将文件名拆分成带路径的文件名和扩展名两个部分,然后返回一个二元组(下节课会讲到元组),二元组中的第二个元素就是文件的后缀名(包含.),如果要去掉后缀名中的.,可以做一个字符串的切片操作,代码如下所示。
1 | from os.path import splitext |
例子3:在终端中显示跑马灯(滚动)文字。 🐱
说明:实现跑马灯文字的原理非常简单,把当前字符串的第一个字符放到要输出的内容的最后面,把从第二个字符开始后面的内容放到要输出的内容的最前面,通过循环重复这个操作,就可以看到滚动起来的文字。两次循环之间的间隔可以通过
time模块的sleep函数来实现,而清除屏幕上之前的输出可以使用os模块的system函数调用系统清屏命令来实现。
1 | import os |
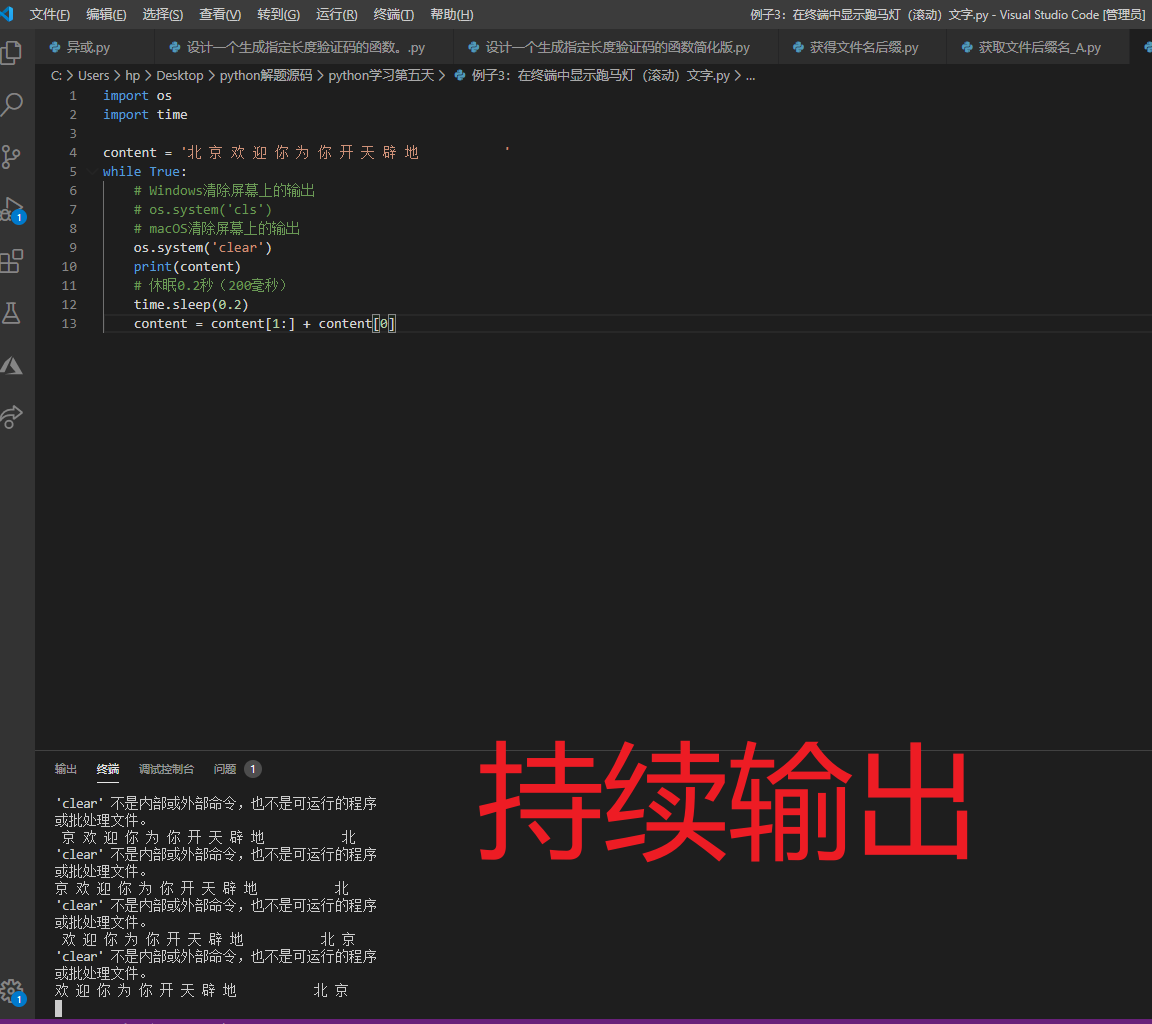
提示:我们之前建议大家暂时用VS Code来编写Python代码,如果你已经提前开始使用PyCharm了,需要提醒大家,PyCharm的运行窗口无法用上面的方式做清屏处理。建议在“命令行提示符”或“终端”(PyCharm中的“Terminal”相当于就是Windows系统的“命令行提示符”或macOS系统的“终端”)中运行该程序。
简单的总结 🏤
在写代码尤其是开发商业项目的时候,一定要有意识的将相对独立且重复出现的功能封装成函数,这样不管是自己还是团队的其他成员都可以通过调用函数的方式来使用这些功能。字符串是非常重要的数据类型,字符串的常用运算和方法需要掌握,因为一般的商业项目中,处理字符串比处理数值的操作要更多。
MRCTF异或
0x01 使用EP查看文件是否加壳 🔑

没有加壳,32位文件
0x02 使用IDA32位打开文件 📉
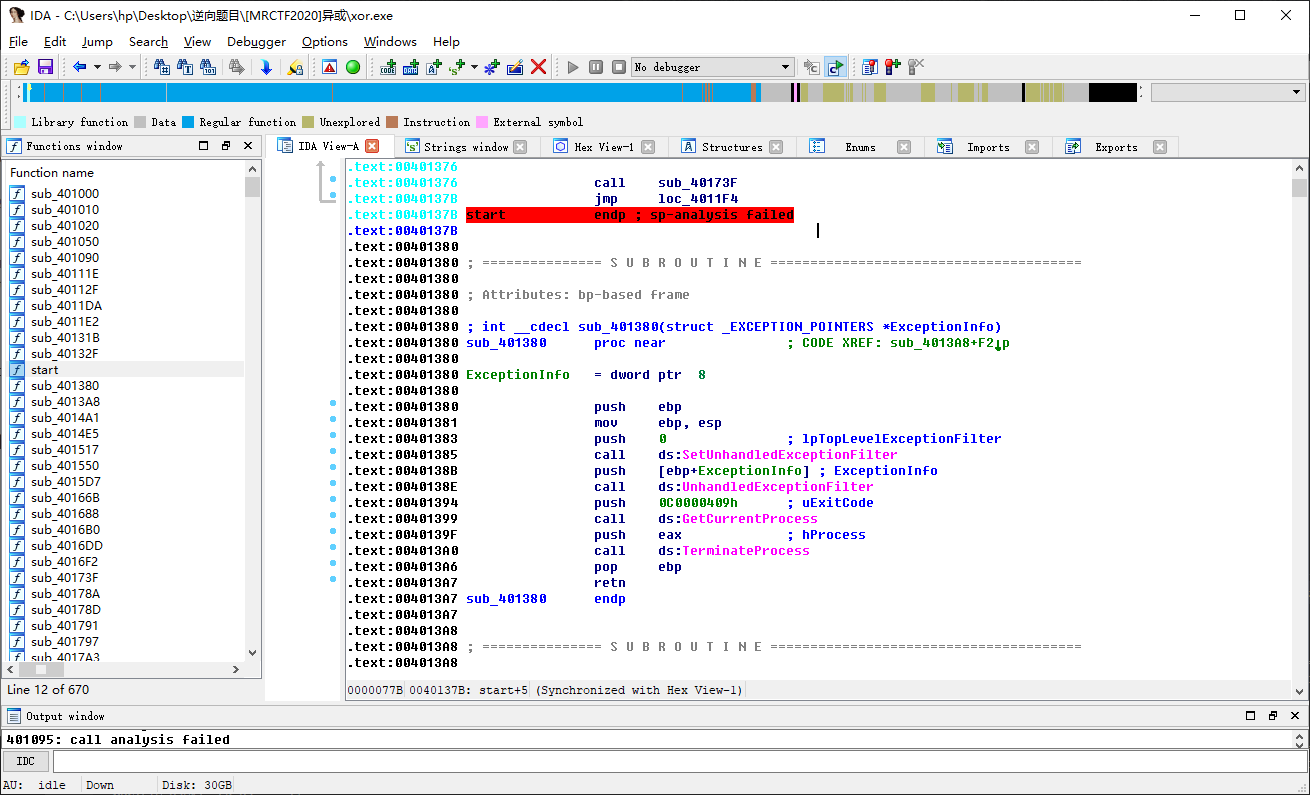
Shift + F12 查找关键函数,然后F5反编译
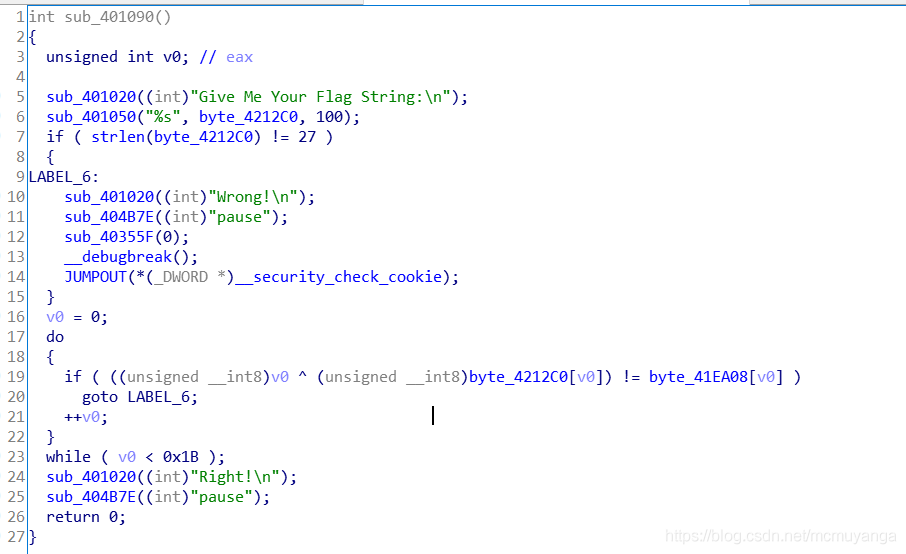
第十九行可知v0和byte_4212c0进行异或,得到byte_41EA08输出正确
直接进入byte_41EA08函数查看内容
得到异或内容
1 | a="MSAWB~FXZ:J:`tQJ\"N@ bpdd}8g" |
0x03 开始构建异或脚本 🔨
1 | a = "MSAWB~FXZ:J:`tQJ\"N@ bpdd}8g" |

1 | MRCTF{@_R3@1ly_E2_R3verse!} |
从零开始学python第四天
从零考试学习python内容 99%来自于python大神 python-jack的知乎文章 再结合本人的实际情况进行学习,严格来说这是JACK老师的内容,只不过再此基础上,我增添了一些我在CTF解题过程中遇到的python脚本实际情况,再次感谢JACK老师
字符串的定义
所谓字符串,就是由零个或多个字符组成的有限序列,一般记为:
在Python程序中,如果我们把单个或多个字符用 单引号 或者 双引号 包围起来,就可以表示一个字符串。字符串中的字符可以是特殊符号、英文字母、中文字符、日文的平假名或片假名、希腊字母、Emoji字符等。
1 | s1 = 'hello, world!' |
提示:
end=''表示输出后不换行,即将默认的结束符\n(换行符)更换为''(空字符)。
转义字符和原始字符串
可以在字符串中使用\(反斜杠)来表示转义,也就是说\后面的字符不再是它原来的意义,例如:\n不是代表反斜杠和字符n,而是表示换行;\t也不是代表反斜杠和字符t,而是表示制表符。所以如果字符串本身又包含了'、"、\这些特殊的字符,必须要通过\进行转义处理。例如需要一个带单引号或反斜杠的字符串,可以用如下所示的方法进行处理。
1 | # 头尾带单引号的hello, world! |
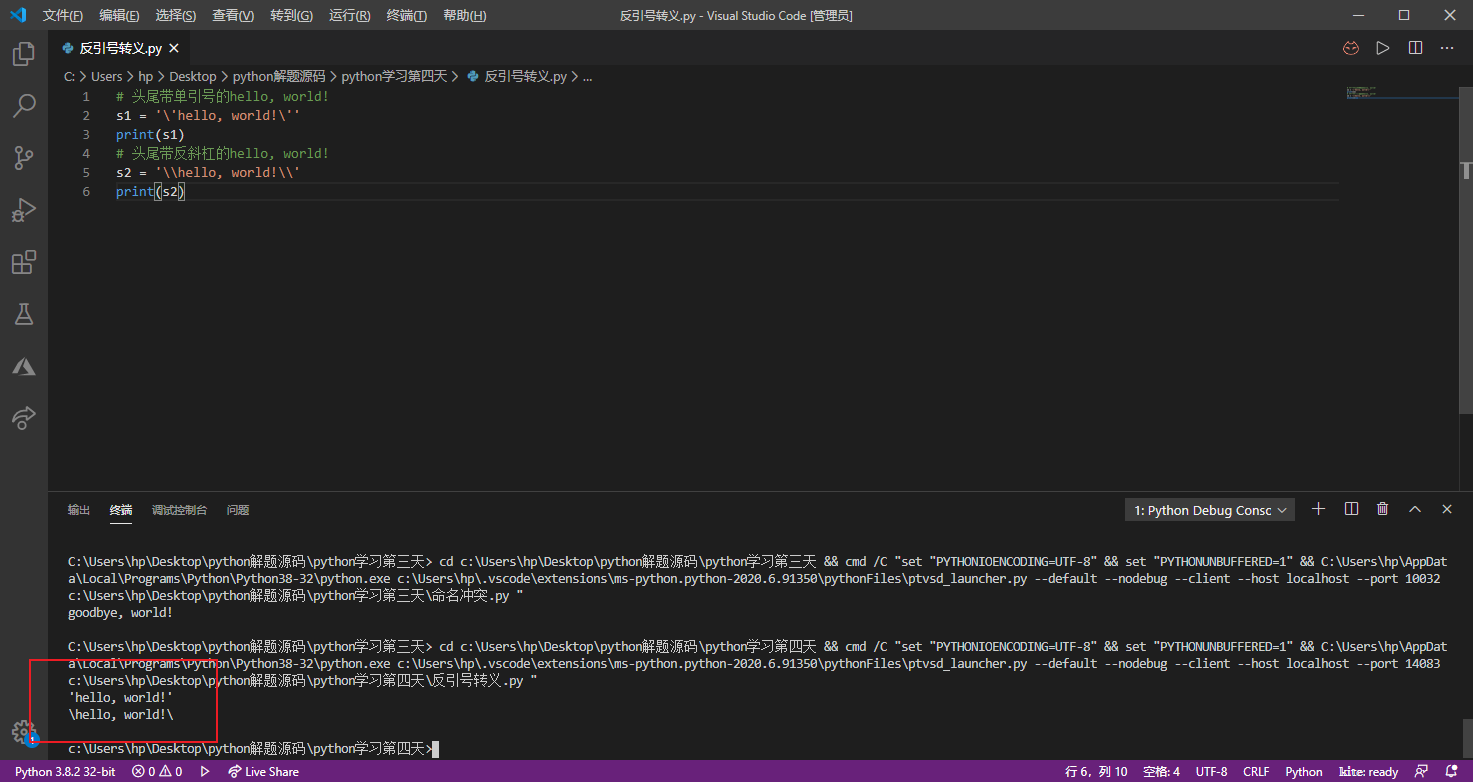
Python中的字符串可以r或R开头,这种字符串被称为原始字符串,意思是字符串中的每个字符都是它本来的含义,没有所谓的转义字符。例如,在字符串'hello\n'中,\n表示换行;而在r'hello\n'中,\n不再表示换行,就是反斜杠和字符n。大家可以运行下面的代码,看看会输出什么。
1 | # 字符串s1中\t是制表符,\n是换行符 |
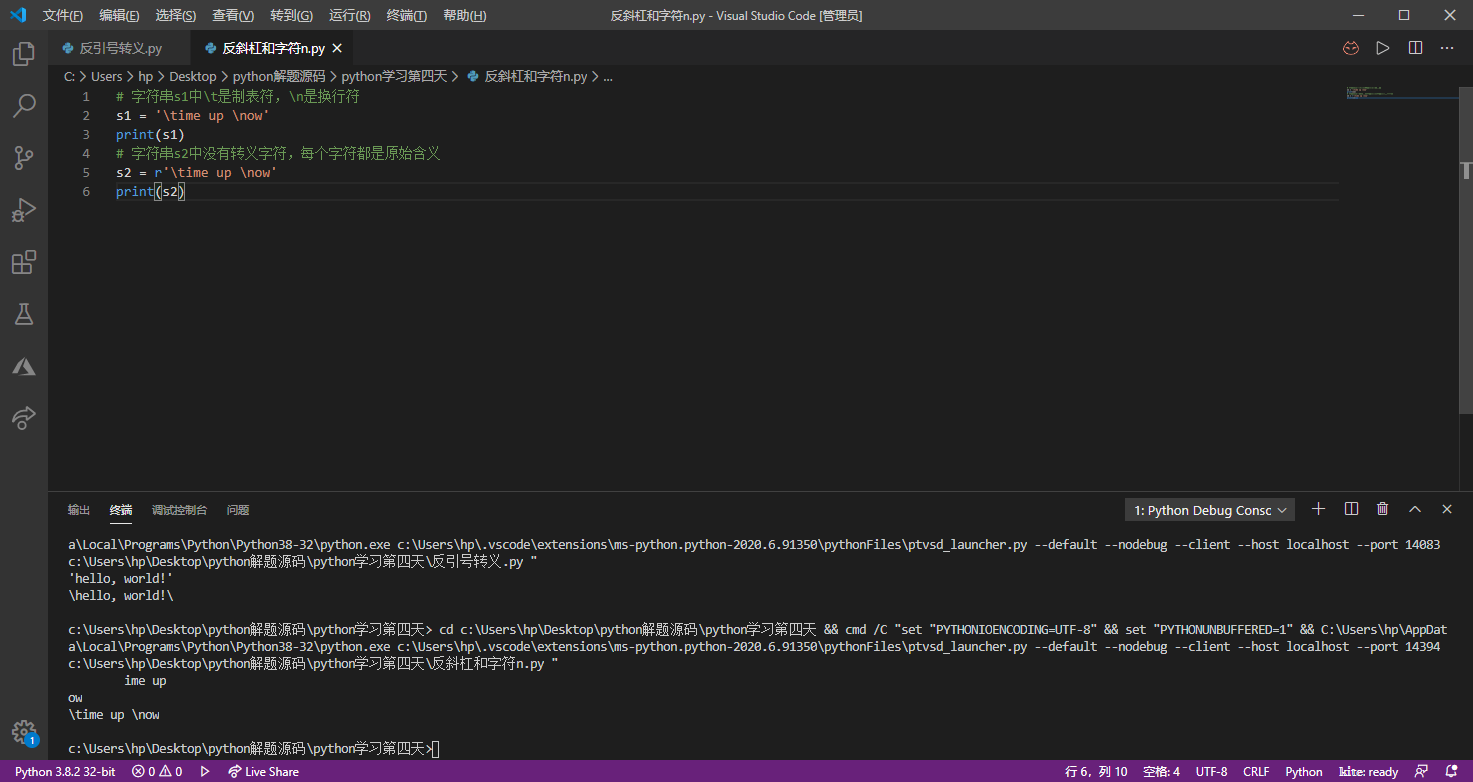
Python中还允许在\后面还可以跟一个八进制或者十六进制数来表示字符,例如\141和\x61都代表小写字母a,前者是八进制的表示法,后者是十六进制的表示法。另外一种表示字符的方式是在\u后面跟Unicode字符编码,例如\u9a86\u660a代表的是中文“骆昊”。运行下面的代码,看看输出了什么。
1 | s1 = '\141\142\143\x61\x62\x63' |
字符串的运算
Python为字符串类型提供了非常丰富的运算符,我们可以使用+运算符来实现字符串的拼接,可以使用*运算符来重复一个字符串的内容,可以使用in和not in来判断一个字符串是否包含另外一个字符串,我们也可以用[]和[:]运算符从字符串取出某个字符或某些字符。
拼接和重复
下面的例子演示了使用+和*运算符来实现字符串的拼接和重复操作。
1 | s1 = 'hello' + ' ' + 'world' |
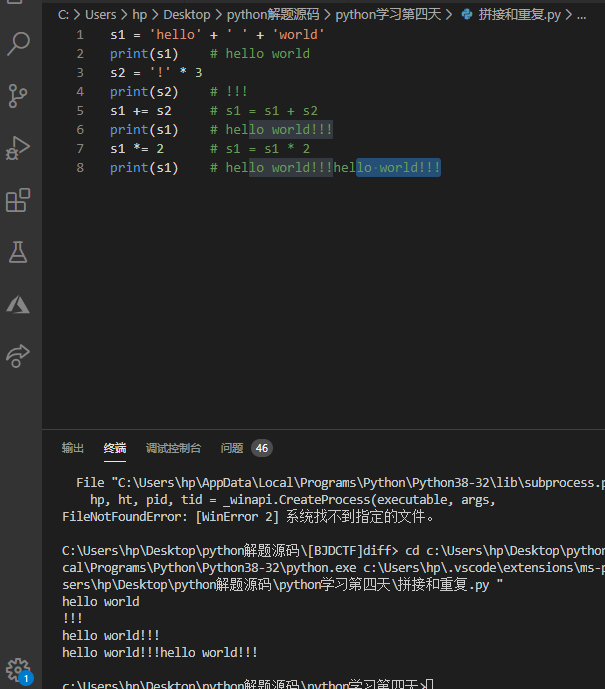
用*实现字符串的重复是非常有意思的一个运算符,在很多编程语言中,要表示一个有10个a的字符串,你只能写成"aaaaaaaaaa",但是在Python中,你可以写成'a' * 10。你可能觉得"aaaaaaaaaa"这种写法也没有什么不方便的,那么想一想,如果字符a要重复100次或者1000次又会如何呢?
比较运算
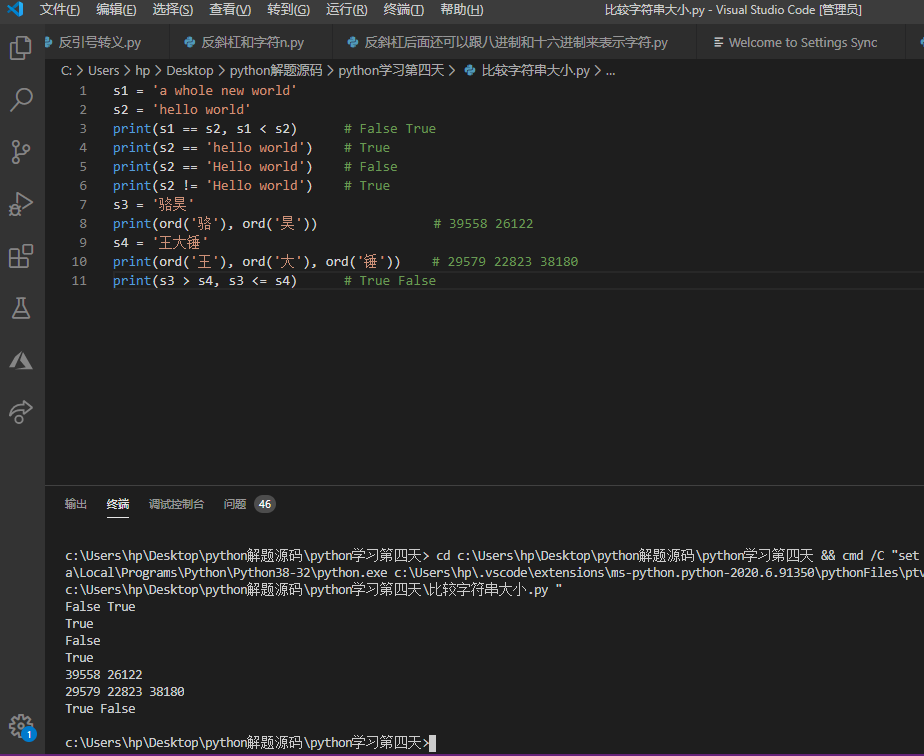
对于两个字符串类型的变量,可以直接使用比较运算符比较两个字符串的相等性或大小。需要说明的是,因为字符串在计算机内存中也是以二进制形式存在的,那么字符串的大小比较比的是每个字符对应的编码的大小。例如A的编码是65, 而a的编码是97,所以'A' < 'a'的结果相当于就是65 < 97的结果,很显然是True;而'boy' < 'bad',因为第一个字符都是'b'比不出大小,所以实际比较的是第二个字符的大小,显然'o' < 'a'的结果是False,所以'boy' < 'bad'的结果也是False。如果不清楚两个字符对应的编码到底是多少,可以使用ord函数来获得,例如ord('A')的值是65,而ord('昊')的值是26122。下面的代码为大家展示了字符串的比较运算。
1 | s1 = 'a whole new world' |
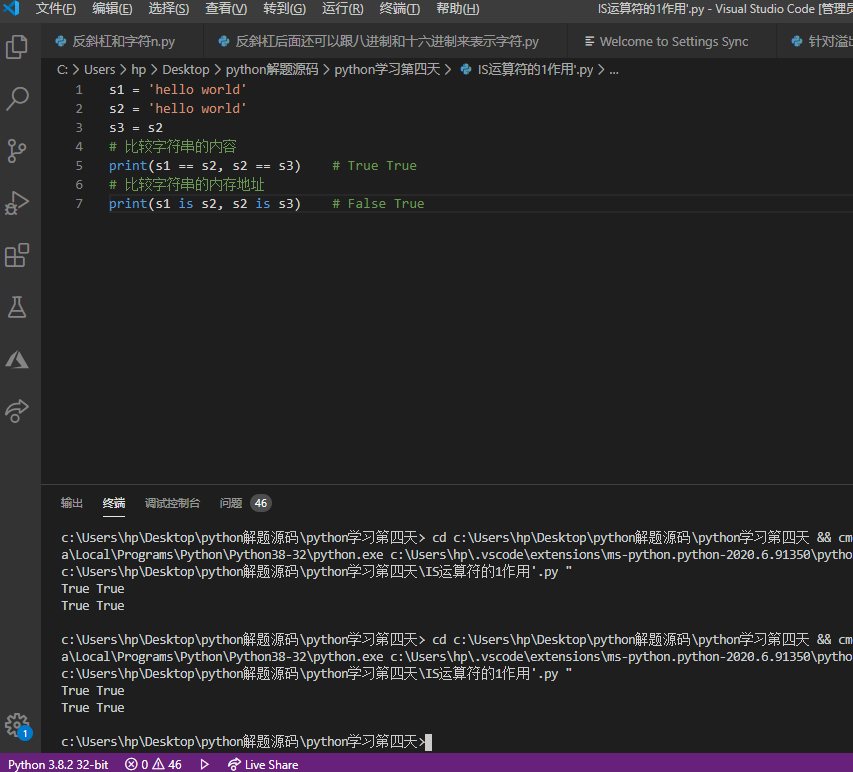
需要强调一下的是,字符串的比较运算比较的是字符串的内容,Python中还有一个is运算符(身份运算符),如果用is来比较两个字符串,它比较的是两个变量对应的字符串是否在内存中相同的位置(内存地址),简单的说就是两个变量是否对应内存中的同一个字符串。看看下面的代码就比较清楚is运算符的作用了。
1 | s1 = 'hello world' |
成员运算
Python中可以用in和not in判断一个字符串中是否存在另外一个字符或字符串,in和not in运算通常称为成员运算,会产生布尔值True或False,代码如下所示。
1 | s1 = 'hello, world' |
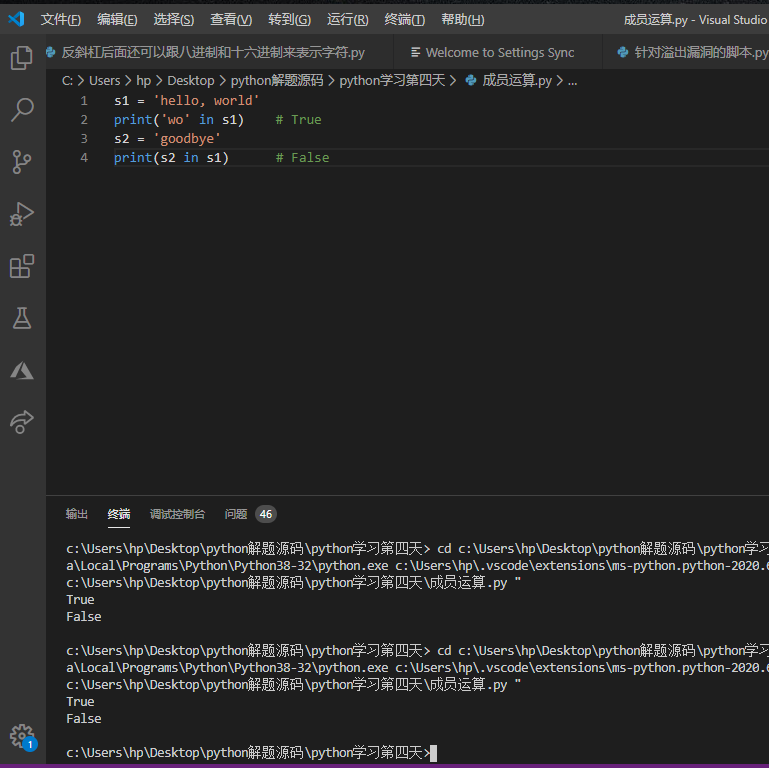
获取字符串长度
获取字符串长度没有直接的运算符,而是使用内置函数len,我们在上节课的提到过这个内置函数,代码如下所示。
BJDCTFdiff2
0x01 用EP打开,查看加壳没
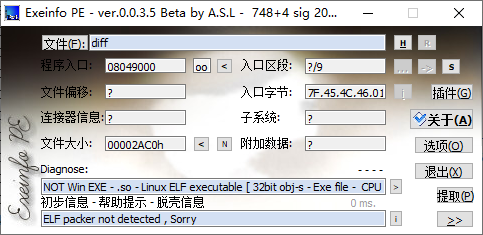
没有加壳
0x02 用IDA32位打开,F5反编译
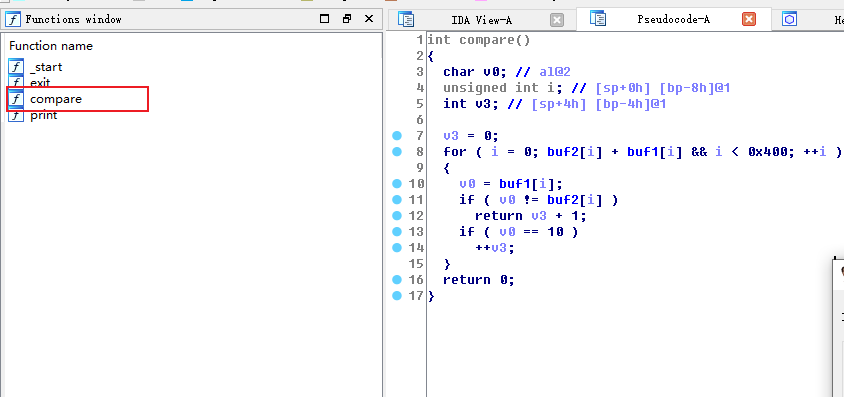
漏洞的地方只可能是 compare
0x03 分析代码
1 | int compare() |
char型变量占1个字节,相当于unsigned byte,表示范围是0x0-0xff,两个char相加的范围就是0x0 - 0x1fe ,由于char型只能存储1个字节的数据,两个char相加产生的进位就会被忽略。char + char = 溢出 举个栗子,0x7d+0x83=0x100->0x0。
所以如果buf2[i]+buf1[i]=0x100就会 终止 for循环
每次返回一个进行爆破即可
0x04 构造python脚本
1 | from subprocess import * |
从零开始学习python第三天
从零考试学习python内容 99%来自于python大神 python-jack的知乎文章 再结合本人的实际情况进行学习,严格来说这是JACK老师的内容,只不过再此基础上,我增添了一些我在CTF解题过程中遇到的python脚本实际情况,再次感谢JACK老师
函数的作用
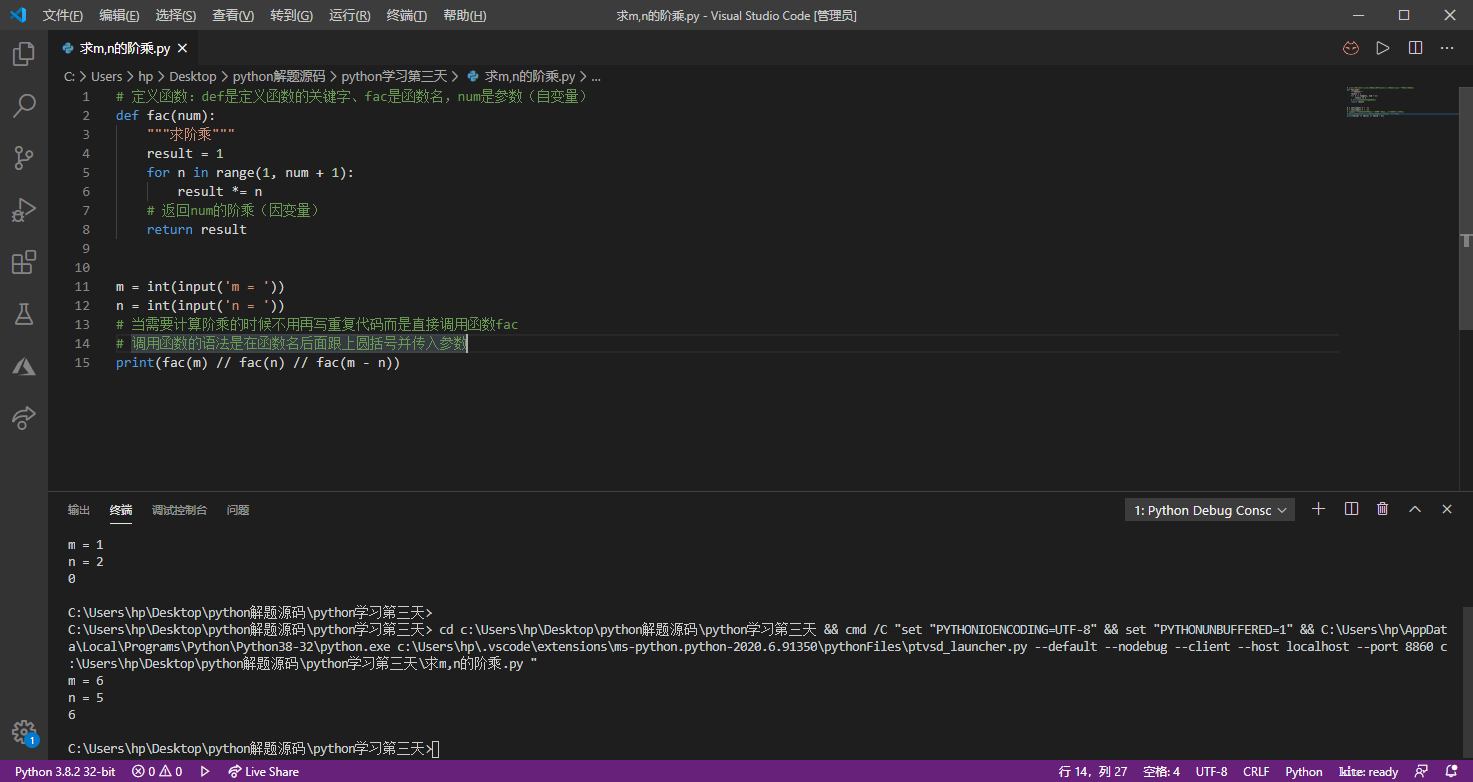
不知大家是否注意到,上面的代码中我们做了三次求阶乘,虽然m、n、m - n的值各不相同,但是三段代码并没有实质性的区别,属于重复代码。世界级的编程大师Martin Fowler先生曾经说过:“代码有很多种坏味道,重复是最坏的一种!”。要写出高质量的代码首先要解决的就是重复代码的问题。对于上面的代码来说,我们可以将计算阶乘的功能封装到一个称为“函数”的代码块中,在需要计算阶乘的地方,我们只需要“调用函数”就可以了。
定义函数
数学上的函数通常形如 或者
这样的形式,在
中,
f是函数的名字,x是函数的自变量,y是函数的因变量;而 中,
g是函数名,x和y是函数的自变量,z是函数的因变量。Python中的函数跟这个结构是一致的,每个函数都有自己的名字、自变量和因变量。我们通常把Python中函数的自变量称为函数的参数,而因变量称为函数的返回值。
在Python中可以使用def关键字来定义函数,和变量一样每个函数也应该有一个漂亮的名字,命名规则跟变量的命名规则是一致的。在函数名后面的圆括号中可以放置传递给函数的参数,就是我们刚才说到的函数的自变量,而函数执行完成后我们会通过return关键字来返回函数的执行结果,就是我们刚才说的函数的因变量。一个函数要执行的代码块(要做的事情)也是通过缩进的方式来表示的,跟之前分支和循环结构的代码块是一样的。大家不要忘了def那一行的最后面还有一个:,之前提醒过大家,那是在英文输入法状态下输入的冒号。
我们可以通过函数对上面的代码进行重构。**所谓重构,是在不影响代码执行结果的前提下对代码的结构进行调整。**重构之后的代码如下所示。
1 | """ |
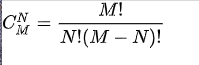
函数的参数
参数的默认值
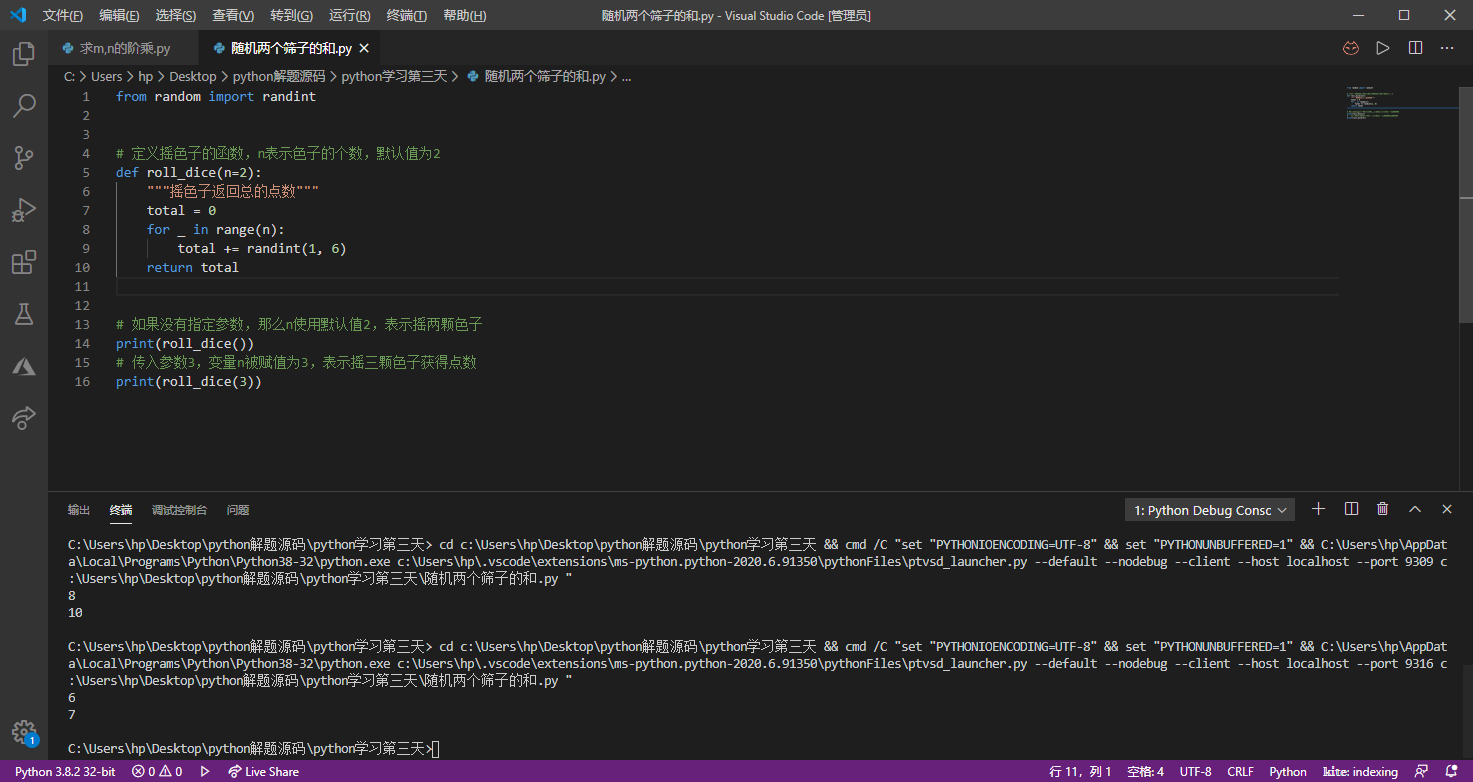
如果函数中没有return语句,那么函数默认返回代表空值的None。另外,在定义函数时,函数也可以没有自变量,但是函数名后面的圆括号是必须有的。Python中还允许函数的参数拥有默认值,我们可以把上一课“CRAPS赌博游戏”的摇色子获得点数的功能封装成函数,代码如下所示。
1 | """ |
我们再来看一个更为简单的例子。
1 | """ |
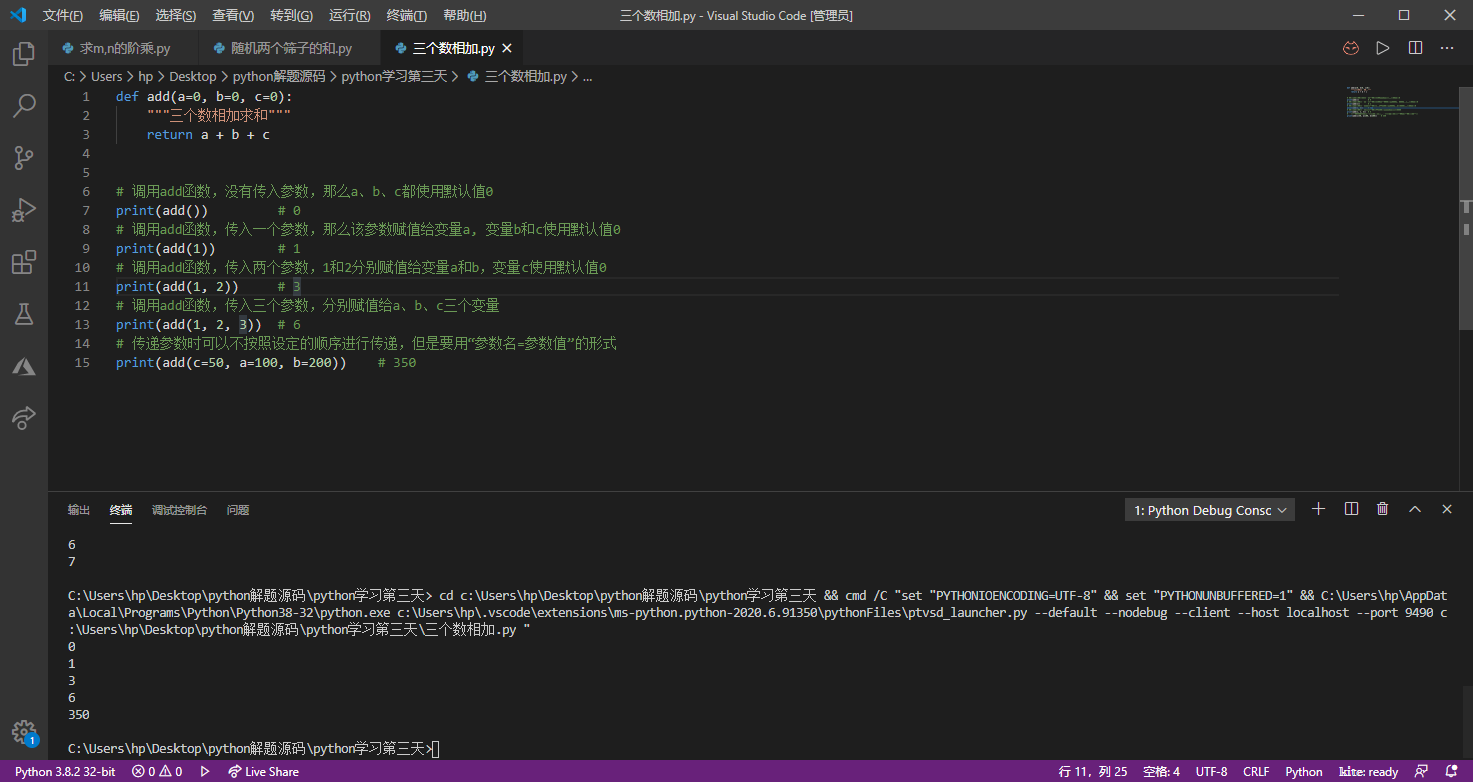
注意:带默认值的参数必须放在不带默认值的参数之后,否则将产生
SyntaxError错误,错误消息是:non-default argument follows default argument,翻译成中文的意思是“没有默认值的参数放在了带默认值的参数后面”。
可变参数
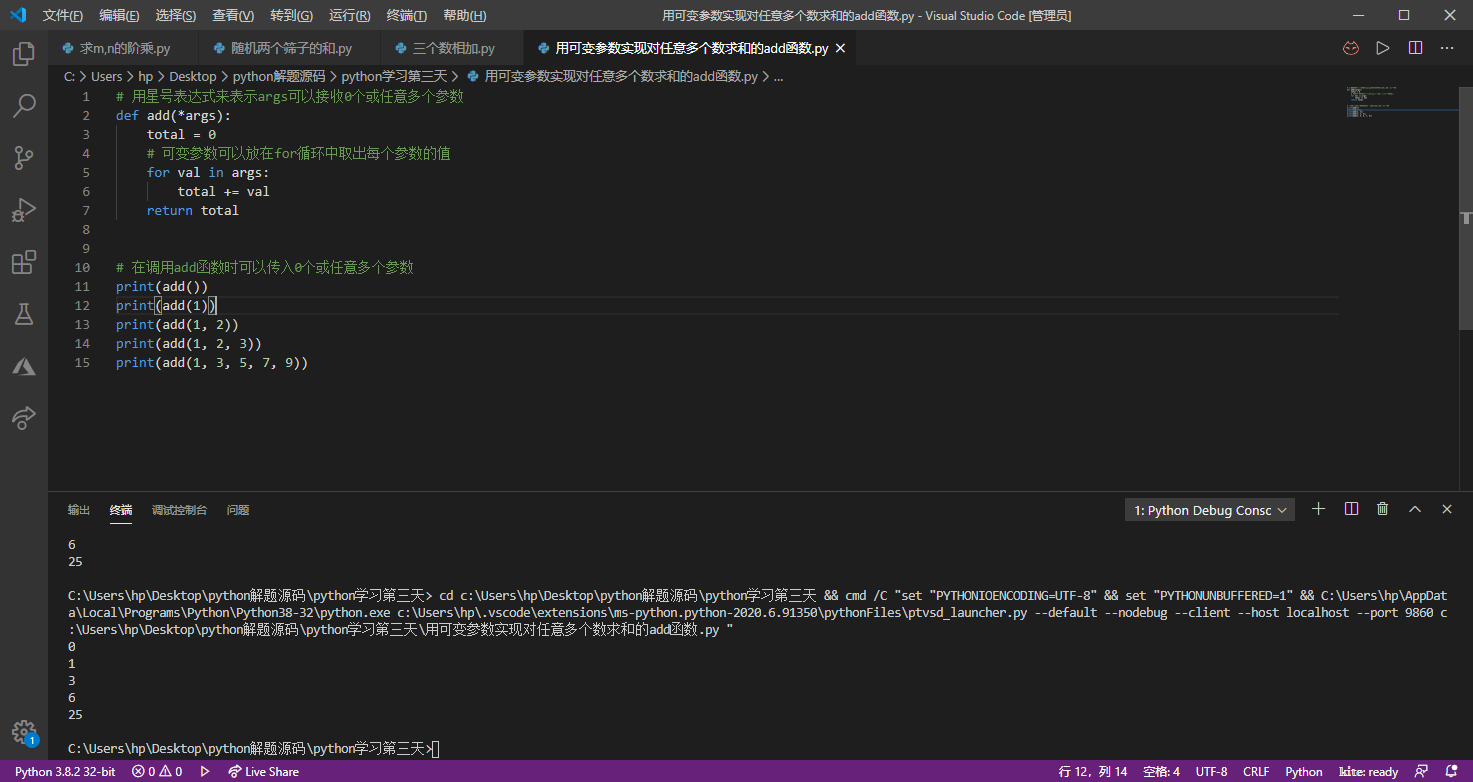
接下来,我们还可以实现一个对任意多个数求和的add函数,因为Python语言中的函数可以通过星号表达式语法来支持可变参数。所谓可变参数指的是在调用函数时,可以向函数传入0个或任意多个参数。将来我们以团队协作的方式开发商业项目时,很有可能要设计函数给其他人使用,但有的时候我们并不知道函数的调用者会向该函数传入多少个参数,这个时候可变参数就可以派上用场。下面的代码演示了用可变参数实现对任意多个数求和的add函数。
1 | """ |
用模块管理函数
不管用什么样的编程语言来写代码,给变量、函数起名字都是一个让人头疼的问题,因为我们会遇到命名冲突这种尴尬的情况。最简单的场景就是在同一个.py文件中定义了两个同名的函数,如下所示。
1 | def foo(): |
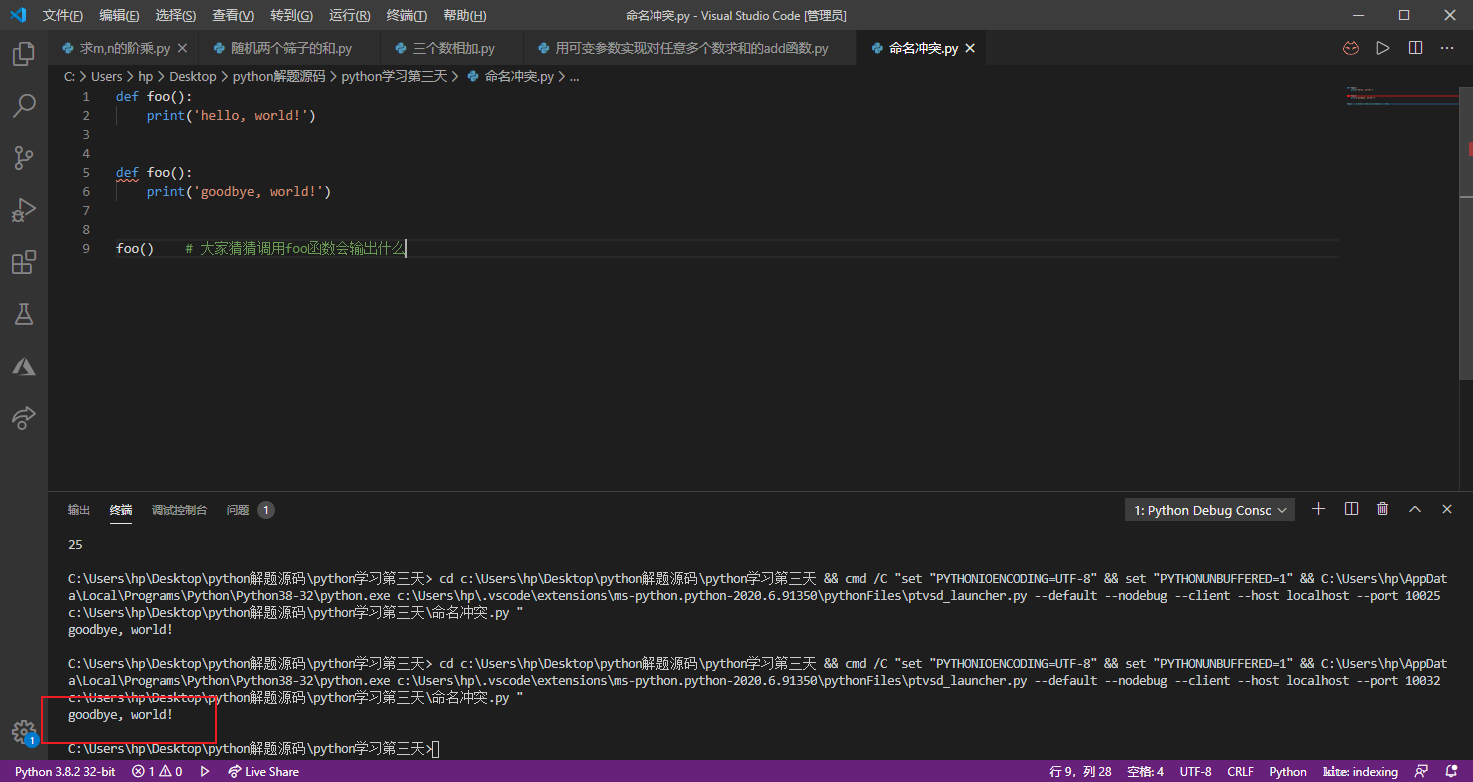
当然上面的这种情况我们很容易就能避免,但是如果项目是团队协作多人开发的时候,团队中可能有多个程序员都定义了名为foo的函数,这种情况下怎么解决命名冲突呢?答案其实很简单,Python中每个文件就代表了一个模块(module),我们在不同的模块中可以有同名的函数,在使用函数的时候我们通过import关键字导入指定的模块再使用完全限定名的调用方式就可以区分到底要使用的是哪个模块中的foo函数,代码如下所示。
module1.py
1 | def foo(): |
module2.py
1 | def foo(): |
test.py
1 | import module1 |
在导入模块时,还可以使用as关键字对模块进行别名,这样我们可以使用更为简短的完全限定名。
test.py
1 | import module1 as m1 |
上面的代码我们导入了定义函数的模块,我们也可以使用from...import...语法从模块中直接导入需要使用的函数,代码如下所示。
test.py
1 | from module1 import foo |
但是,如果我们如果从两个不同的模块中导入了同名的函数,后导入的函数会覆盖掉先前的导入,就像下面的代码中,调用foo会输出hello, world!,因为我们先导入了module2的foo,后导入了module1的foo 。如果两个from...import...反过来写,就是另外一番光景了。
test.py
1 | from module1 import foo as f1 |
标准库中的模块和函数
Python标准库中提供了大量的模块和函数来简化我们的开发工作,我们之前用过的random模块就为我们提供了生成随机数和进行随机抽样的函数;而time模块则提供了和时间操作相关的函数;上面求阶乘的函数在Python标准库中的math模块中已经有了,实际开发中并不需要我们自己编写,而math模块中还包括了计算正弦、余弦、指数、对数等一系列的数学函数。随着我们进一步的学习Python编程知识,我们还会用到更多的模块和函数。
Python标准库中还有一类函数是不需要import就能够直接使用的,我们将其称之为内置函数,这些内置函数都是很有用也是最常用的,下面的表格列出了一部分的内置函数。
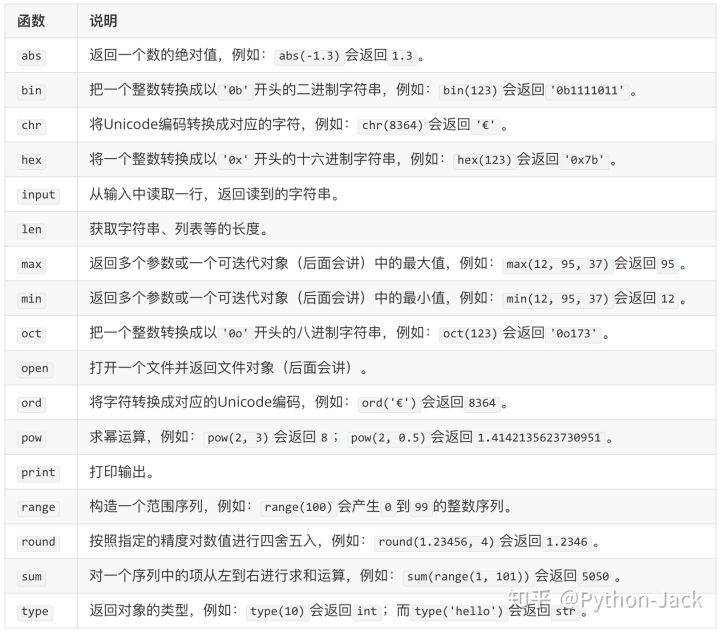
简单的总结
函数是功能相对独立且会重复使用的代码的封装。学会使用定义和使用函数,就能够写出更为优质的代码。当然,Python语言的标准库中已经为我们提供了大量的模块和常用的函数,用好这些模块和函数就能够用更少的代码做更多的事情。
BJDCTF8086
链接:https://pan.baidu.com/s/12-rOdMS1Lyz0Fc-tGxu5hQ
提取码:ex3u
0X01 使用EP查看文件是否有无加壳
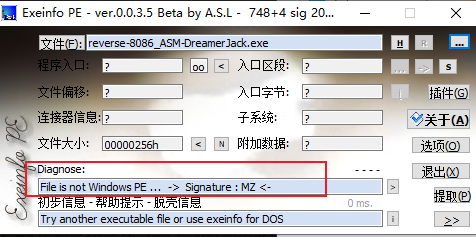
没有加壳,直接拖到64位IDA上面
0x02 查看sub_10030函数
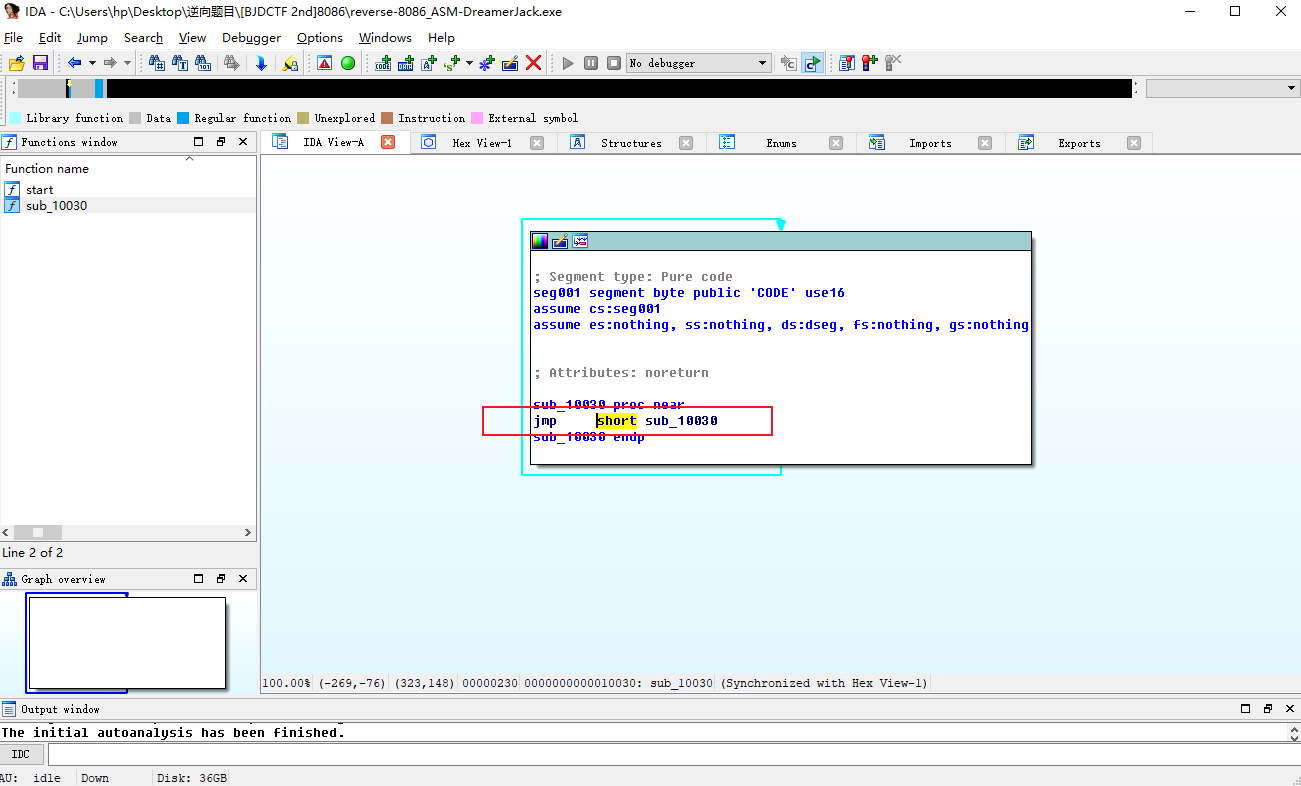
点击进去看看
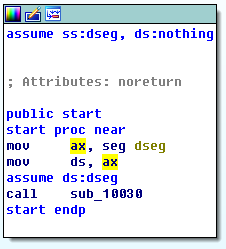
发现是个死循环函数,重复跳转自身
0x02 使用IDA32位打开文件
- Shift+F12查看直观函数

- F5反编译,发现已经反编译,就无需反编译
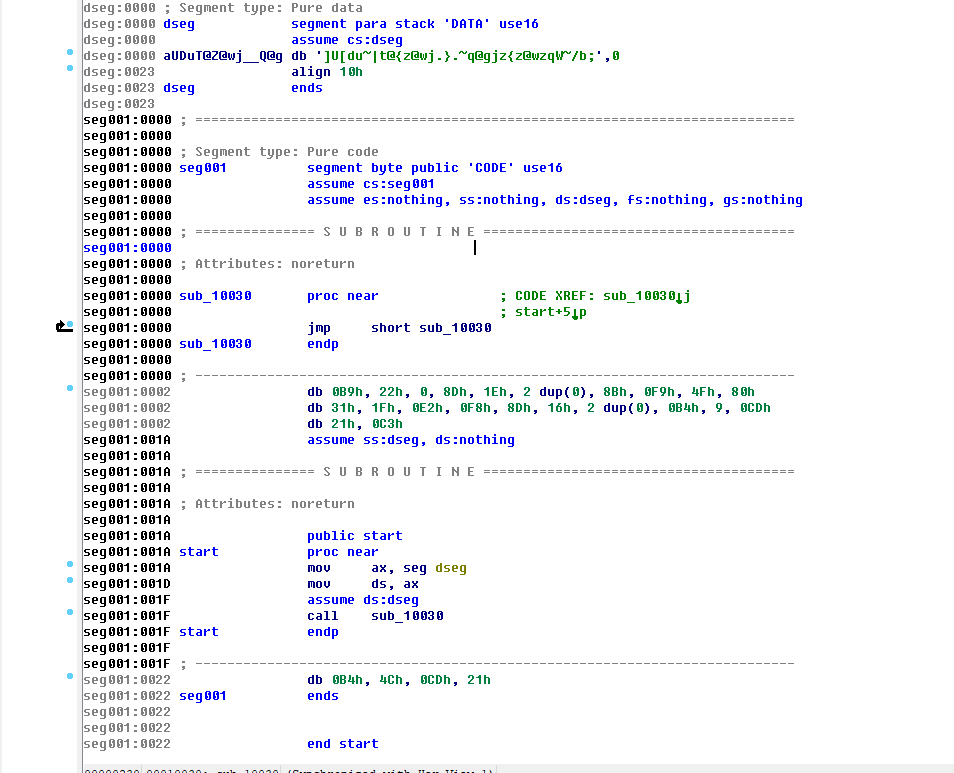
- 分析头函数数据

- 分析sub_10030函数,重复跳转自身的死循环,节选后,按住
C键开始强制汇编(Force)
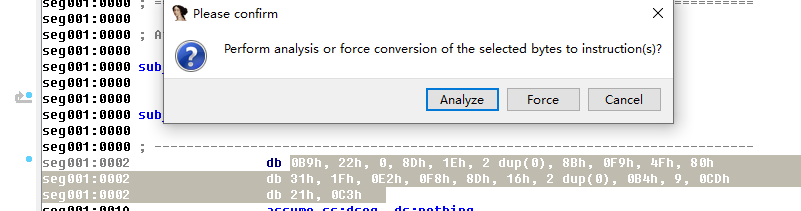
0x03 开始分析强制汇编的内容

0x04 开始构建脚本与0X1F做异或
1 | a = "]U[du~|t@{z@wj.}.~q@gjz{z@wzqW~/b" |
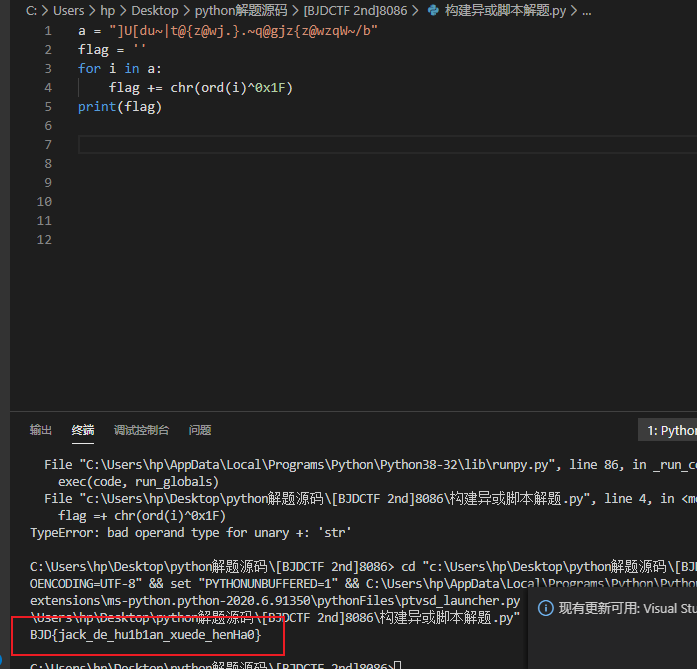
1 | BJD{jack_de_hu1b1an_xuede_henHa0} |
从零开始学python第二天
从零考试学习python内容 99%来自于python大神 python-jack的知乎文章 再结合本人的实际情况进行学习,严格来说这是JACK老师的内容,只不过再此基础上,我增添了一些我在CTF解题过程中遇到的python脚本实际情况,再次感谢JACK老师
for-in循环
如果明确的知道循环执行的次数,我们推荐使用for-in循环,例如计算1到100的和。 被for-in循环控制的语句块也是通过缩进的方式来确定的,这一点跟分支结构完全相同,大家看看下面的代码就明白了。
1 | """ |
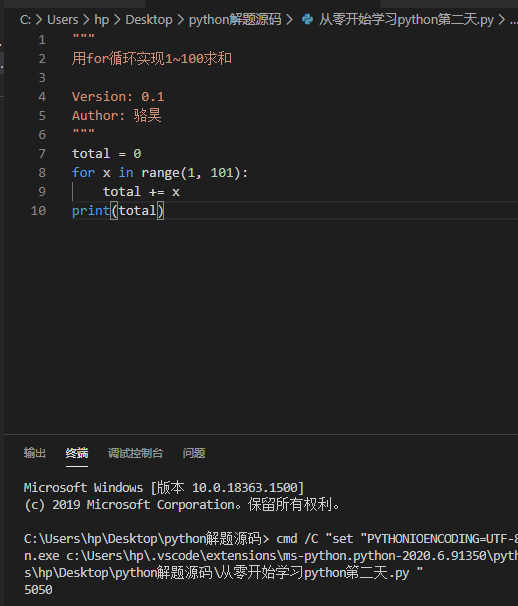
需要说明的是上面代码中的range(1, 101)可以用来构造一个从1到100的范围,当我们把这样一个范围放到for-in循环中,就可以通过前面的循环变量x依次取出从1到100的整数。当然,range的用法非常灵活,下面给出了一个例子:
range(101):可以用来产生0到100范围的整数,需要注意的是取不到101。range(1, 101):可以用来产生1到100范围的整数,相当于前面是闭区间后面是开区间。range(1, 101, 2):可以用来产生1到100的奇数,其中2是步长,即每次数值递增的值。range(100, 0, -2):可以用来产生100到1的偶数,其中-2是步长,即每次数字递减的值。
知道了这一点,我们可以用下面的代码来实现1~100之间的偶数求和。
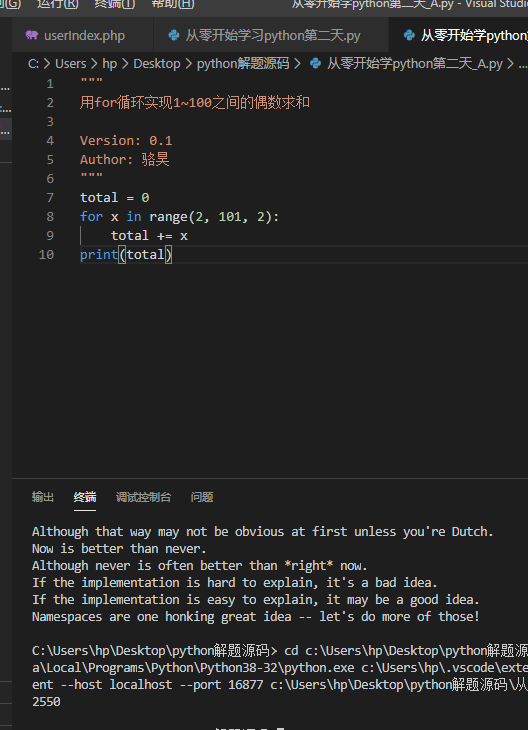
while循环
如果要构造不知道具体循环次数的循环结构,我们推荐使用while循环。while循环通过一个能够产生或转换出bool值的表达式来控制循环,表达式的值为True则继续循环;表达式的值为False则结束循环。
下面我们通过一个“猜数字”的小游戏来看看如何使用while循环。猜数字游戏的规则是:计算机出一个1到100之间的随机数,玩家输入自己猜的数字,计算机给出对应的提示信息(大一点、小一点或猜对了),如果玩家猜中了数字,计算机提示用户一共猜了多少次,游戏结束,否则游戏继续。
1 | """ |
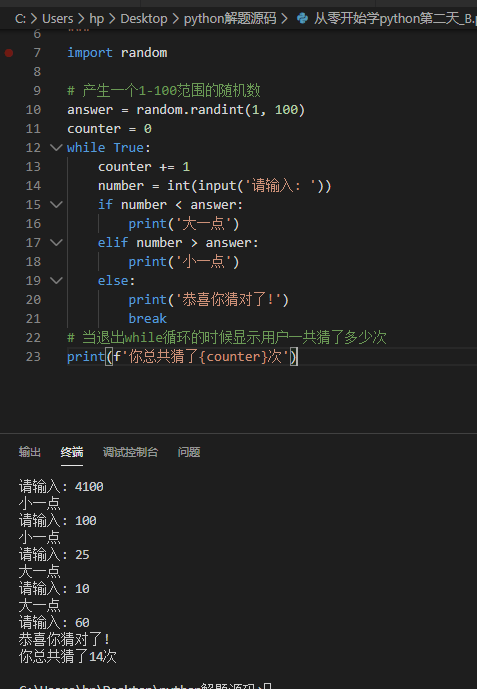
break和continue
上面的代码中使用while True构造了一个条件恒成立的循环,也就意味着如果不做特殊处理,循环是不会结束的,这也就是常说的“死循环”。为了在用户猜中数字时能够退出循环结构,我们使用了break关键字,它的作用是提前结束循环。需要注意的是,break只能终止它所在的那个循环,这一点在使用嵌套循环结构时需要引起注意,下面的例子我们会讲到什么是嵌套的循环结构。除了break之外,还有另一个关键字是continue,它可以用来放弃本次循环后续的代码直接让循环进入下一轮。
嵌套的循环结构
和分支结构一样,循环结构也是可以嵌套的,也就是说在循环中还可以构造循环结构。下面的例子演示了如何通过嵌套的循环来输出一个乘法口诀表(九九表)
1 | """ |
很显然,在上面的代码中,外层循环用来控制一共会产生9行的输出,而内层循环用来控制每一行会输出多少列。内层循环中的输出就是九九表一行中的所有列,所以在内层循环完成时,有一个print()来实现换行输出的效果。
循环的例子
例子1:输入一个正整数判断它是不是素数。
提示:素数指的是只能被1和自身整除的大于1的整数。
1 | """ |
SWPU2019 Web4
无论URL还是界面都很有SQL的feeling,,点击注册,发现无法提供注册,使用密码本爆破也失败(应该有过滤)
0x01 抓包
- 我们账号和密码都输入admin,开始发包和抓包
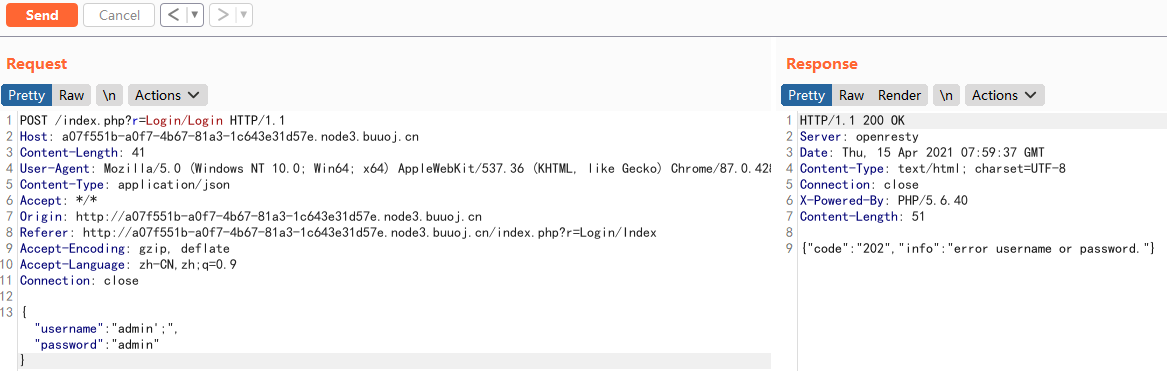
界面很容易让人想起SQL注入,由于登陆没反应,我们直接抓包,因为之前堆叠注入做过几道题(buuctf 极客大挑战),还是比较熟悉判断方法
存在堆叠注入的判断方法 : 名称处加单引号报错,加双引号不报错,加单引号和分号不报错,说明存在堆叠注入。
根据判断方法,当我们在 username 输入 admin' 或者 admin;' ,提示报错

当我们在 username 输入:admin 或者 admin’; 报错消失
我们先引来引入php中的PDO知识点
0x02 先来讲一下什么是PDO
https://www.runoob.com/php/php-pdo.html
默认是pdo对象的query语句是能执行有;参与的多语句执行的,那我们就能闭合前面的单引号后进行堆叠注入。
0x03 由于我们没收到特殊回显和被过滤掉了许多关键字。我们构造的脚本考虑采用十六进制加预处理加上时间盲注进行绕过
- 为什么用十六进制SQL预处理语句+时间盲注来绕过
因为SQL关键字被绕过而且回显并不特别的情况下再加上某些单词如 select,if.sleep 必须使用,盲注考虑后觉得时间盲注可能性比较大
- 时间盲注思路
select if(ascii(substr((select flag from flag),{0},1))={1},sleep(5),1) ,{0} 猜测字段的长度 , {1} 是32-128的ascii数值(用来盲注爆破)
-
防止SQL预处理被过滤
使用16进制
如下
1 | mysql> select hex('select sleep(5)'); |
select sleep(5) 语句可以让mysql服务休息5秒。这里这四句相当于执行了该语句,从而绕过上传被过滤的字符串。
在SQL测试中发现确实可以执行
通过mysql预处理与hex绕过过滤来过滤脚本
1 | #author: c1e4r |
下载获得的源码 URL+glzjin_wants_a_girl_friend.zip
0x04开始对源码进行代码审计
前端应用逻辑的基础在 controller 文件夹下面,而其他文件都是基于 basecontroller.php 所以我们打开 basecontroller.php 文件进行代码审计
1 | private $viewPath; |
extract 传入 viewdata 数组造成变量覆盖,发现利用 loadView 方法的并且第二个元素可控的地方只有 UserController.php
1 | public function actionIndex() |
在Controller/UserController.php中,找到可控制的参数$listData,直接来源于$_REQUEST。 由于 $listData = $_REQUEST; 可以控制 到 userIndex.php 文件看看
1 | <div class="fakeimg"><?php |
这里的$img_file的值可利用前面的逻辑进行覆盖,传入img_file=./…/flag.php即可,而又因为下面的路由控制
1 | // 路由控制跳转至控制器 |
上面可以知道我们传入的路由 r-User/Index
0x05 我们构造playload
GET: index.php?r=User/Index
POST: img_file=/../flag.php
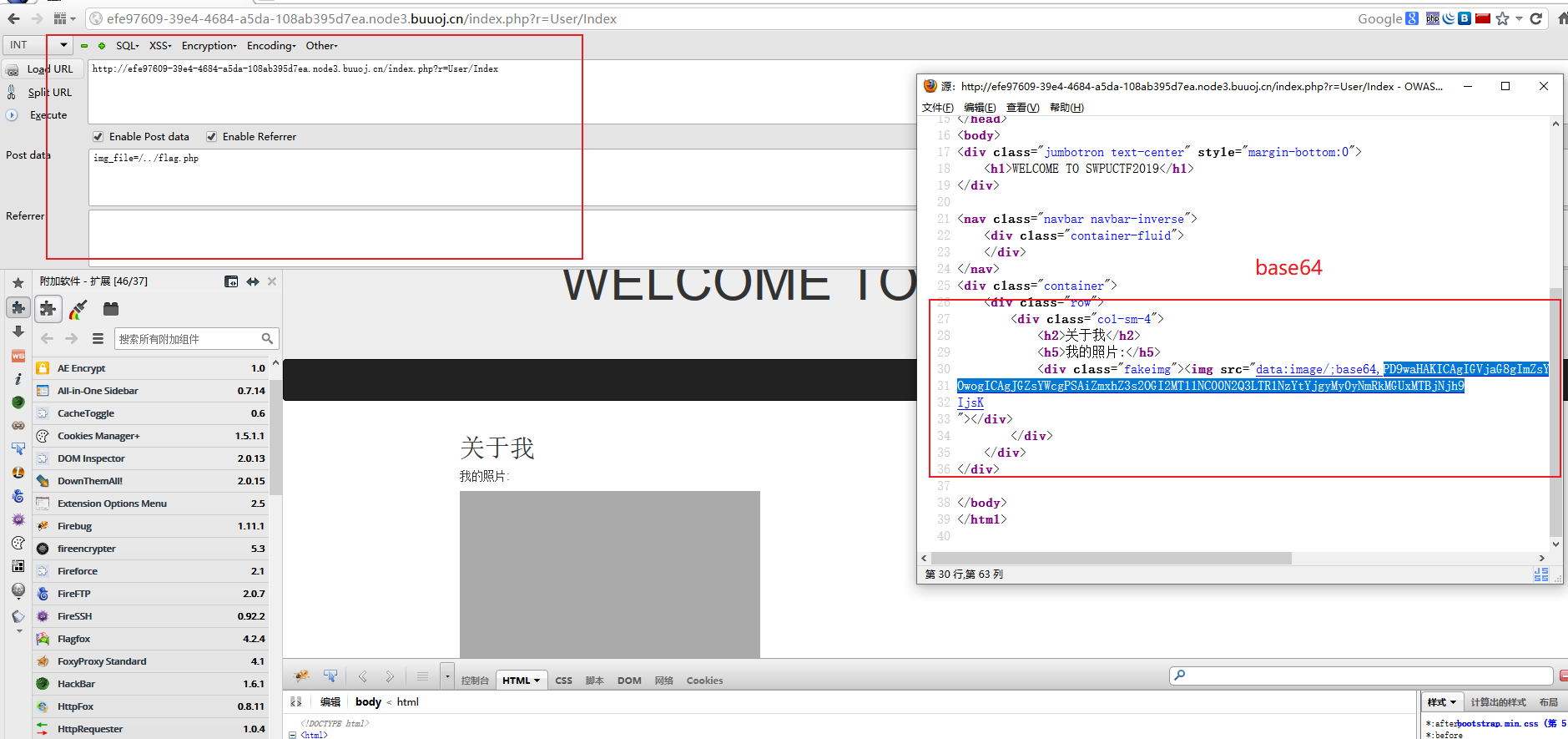

1 | flag{68b619e4-47d7-4e76-b823-26dd0e110c68} |